
Design and Realization of the Distributed Data Center of Full-view Synchronized Measurement System
-
摘要: 源网荷全景同步测量系统(full-view synchronized measurement system,SYMS)实现了对高比例电力电子化的新型电力系统的全方位实时检测。SYMS 主站作为测量数据的接收与分析平台,其数据处理能力对保障SYMS稳定运行与应用效果具有重要意义。然而,由于数据类型多、装置数量激增、数据分析过程复杂,集中式架构的主站难以保证同步相量数据处理的实时性与可靠性。因此,本文提出一种适用于SYMS系统的分布式主站设计方法,并进行了实现。首先,该方法分析了SYMS不同测量装置的通信方式,提出并建立了基于开源相量数据集中器(open source phasor data concentrator,OpenPDC)的多源异类数据适配器,并设计实现了基于HAProxy的主站前置服务器的负载均衡集群;其次,针对主站数据在线分析延时高的问题,设计并开发了基于流处理框架的Storm适配多语言、多时间窗算法的分布式计算方式,进一步搭建了包含前置数据平台与在线应用平台的SYMS分布式主站。实际系统测试结果表明,与集中式架构相比,所提架构在实际运行中可有效均衡负载,利用分布式方式提高运算速度,针对多类型实时测量数据具有更强的并发处理能力与更短的处理延时,并有效监测系统的异常状态,可为新型电力系统特性分析、建模、闭环控制等应用提供数据基础与应用平台。
-
关键词:
- 源网荷全景同步测量系统 /
- 分布式架构 /
- 主站 /
- OpenPDC /
- Storm
Abstract: The full-view synchronized measurement system (SYMS) has realized the all-directional real-time detection of power systems with high proportion of power electronics. As a platform for receiving and analyzing measurement data, the data processing ability of the SYMS master station is of great significance to ensure the stable operation and application effect of the SYMS. However, due to the reasons as the large number of data types, the surge in the number of devices, and the complexity of the data analysis process, it is difficult for SYMS master station with a centralized architecture to guarantee the real-time performance and reliability of the data processing. Therefore, a distributed master station design method for the SYMS system was proposed and implemented in this paper. Firstly, the proposed method analyzed the communication modes of different measurement devices of SYMS, established a multi-source heterogeneous data adapter based on the open source phasor data concentrator. This paper also designed and implemented a load balancing cluster of the main station front-end server based on the HAProxy. Secondly, aiming at the problem of high delay of the data online analysis of master stations, the Storm based on the stream processing framework was designed and developed to adapt the distributed computing method with multi-language and multi-time window algorithm. The SYMS distributed master station including the pre-data processing platform and the online application platform was further built. The actual system test results show that, compared with the centralized architecture, the proposed architecture can effectively balance the load in actual operation and improve the computing speed through the distributed method. The proposed architecture also have stronger concurrent processing capabilities and shorter delay for multi-type real-time measurement data. Furthermore, it can effectively monitor the abnormal state of the system. Therefore, it can provide the data foundation and application platform for characteristic analysis, modeling, closed-loop control and other applications of the new power system.-
Keywords:
- full-view synchronized measurement system /
- distributed architecture /
- data center /
- OpenPDC /
- Storm
-
高比例可再生能源和高比例电力电子设备正成为电力系统发展的重要趋势和关键特征。电力电子变换装备以其在电能形式及其参数变换方面的灵活性,近年来已广泛应用于可再生能源发电、直流输电、无功补偿等电力系统的输配电环节[1-2],这极大地改变了电力系统的机械特性与动态过程,也为系统的实时监测、机理分析带来了新挑战[3-4]。目前,源网荷全景同步测量系统(full-view synchronized measurement system,SYMS)以同步相量测量技术为基础,将测点布置在源–网–荷三端,实现了对发电、输电、负荷3种场景的同步测量[5],有效提高了新型电力系统的稳定性与可靠性[6]。
主站作为测量系统的数据处理和数据应用服务平台,保证其高效、稳定运行,具有重要意义。目前典型的广域同步测量系统也都针对同步相量数据特点与自身需求,对主站进行了研究与开发。Phadke等[7]提出的传统广域测量系统(wide-area measurement system,WAMS)主站架构在数据处理与应用部分采用双机热备的工作方式,系统可用性高,但实际应用时只有主机单节点处于工作状态,处理压力较大;Li等[8]针对低压电网同步动态监测所开发的WAMS–Light系统主站采用垂直应用架构,基于MySQL搭建实时数据库,历史数据库采用Access,满足了对低压电网的同步测量需求,然而在电力大数据场景下,关系型数据库难以保证数据的有效存储及应用;Gardner[9]等介绍了基于频率干扰记录器的广域频率监测系统(frequency monitoring network,FNET),其主站架构经过两代发展,早期采用分层垂直应用架构,但在大量数据处理时同样存在瓶颈;随后,研究人员以分布式架构为基础,结合开源相量平台OpenPDC与Spark大数据技术改进了架构[10],保证了数据分析的高效性,但前置数据通信服务及实时处理环节都运行在同一个服务器内,造成前端压力过大,系统稳定性难以得到保证。
随着SYMS系统规模的不断扩大,采用集中式架构的SYMS主站系统在数据的通信解析、在线应用等方面出现瓶颈。传统主站系统对集中式架构存在依赖性,系统性能提升主要依靠增加CPU、内存等方式,可扩展空间有限,已无法满足SYMS系统实时性与稳定性要求,亟需设计一个并发处理能力强、横向扩展能力强的新型主站架构。
分布式架构作为一种专门针对海量数据场景的有效解决方案,近年来在多个领域得到了广泛应用。其由部署在不同服务器上的多个节点组成,各节点之间相互通信、相互协同,以实现系统的高效处理。基于分布式文件系统HDFS[11]与并行处理MapReduce[12]技术开发的Hadoop架构[13],在处理大规模数据时展现了其高可靠性与强大的可扩展能力,但其进行批处理的耗时较长,难以满足SYMS系统的实时性要求;区别于面向静态数据的批处理方式,以Apache Storm[14]、Spark Streaming[15]为代表的流处理方式,能够处理不停流入系统数据,在进行数据分析时能更好地保障实时性。在实际运行中,通过分析系统运行特点设计合适架构,利用分布式计算技术实现主站内部业务的分化,利用集群技术针对单一业务优化性能,使新型电力系统大规模上传数据处理速度加快,将为SYMS主站可靠运行提供重要保障。
本文设计了适用于SYMS主站的分布式架构,研究了基于开源相量数据集中器(open source phasor data concentrator,OpenPDC)的多源异类数据实时处理方法,实现了同步相量数据的实时归一化处理。开发了基于Apache Storm的电力系统分布式计算平台,通过搭载多语言算法分析新型电力系统源、网、荷侧实时数据,有效监控系统内异常状态。最终搭建了包含数据接收和实时处理功能的分布式主站。
1. SYMS分布式主站前置数据平台
1.1 SYMS系统多源异类数据分析
近年来,SYMS系统针对不同应用场景,设计研制了不同的同步相量测量装置,包括部署在风电场、光伏电场的新能源场站测量装置(SMD-R)、部署在输电网变电站内部的控制类测量装置(SMD-C),以及部署在用电侧的负荷类测量装置(SMD-L)。图1为SYMS系统整体架构图,由图1可见,位于不同场景的各类同步测量装置会将实时的量测数据上传至附近的局部数据集中器中,再经网络通信传递给SYMS主站。目前,SYMS主站已接入SMD装置上百台,单日数据接收量可达20 GB左右,这些同步相量数据可以被实时展示、分析,对电力系统实现了良好的观测效果。目前,全国多地已经接入一定数量的SMD装置,从数据源来看,数据整体呈现出多源化特征。
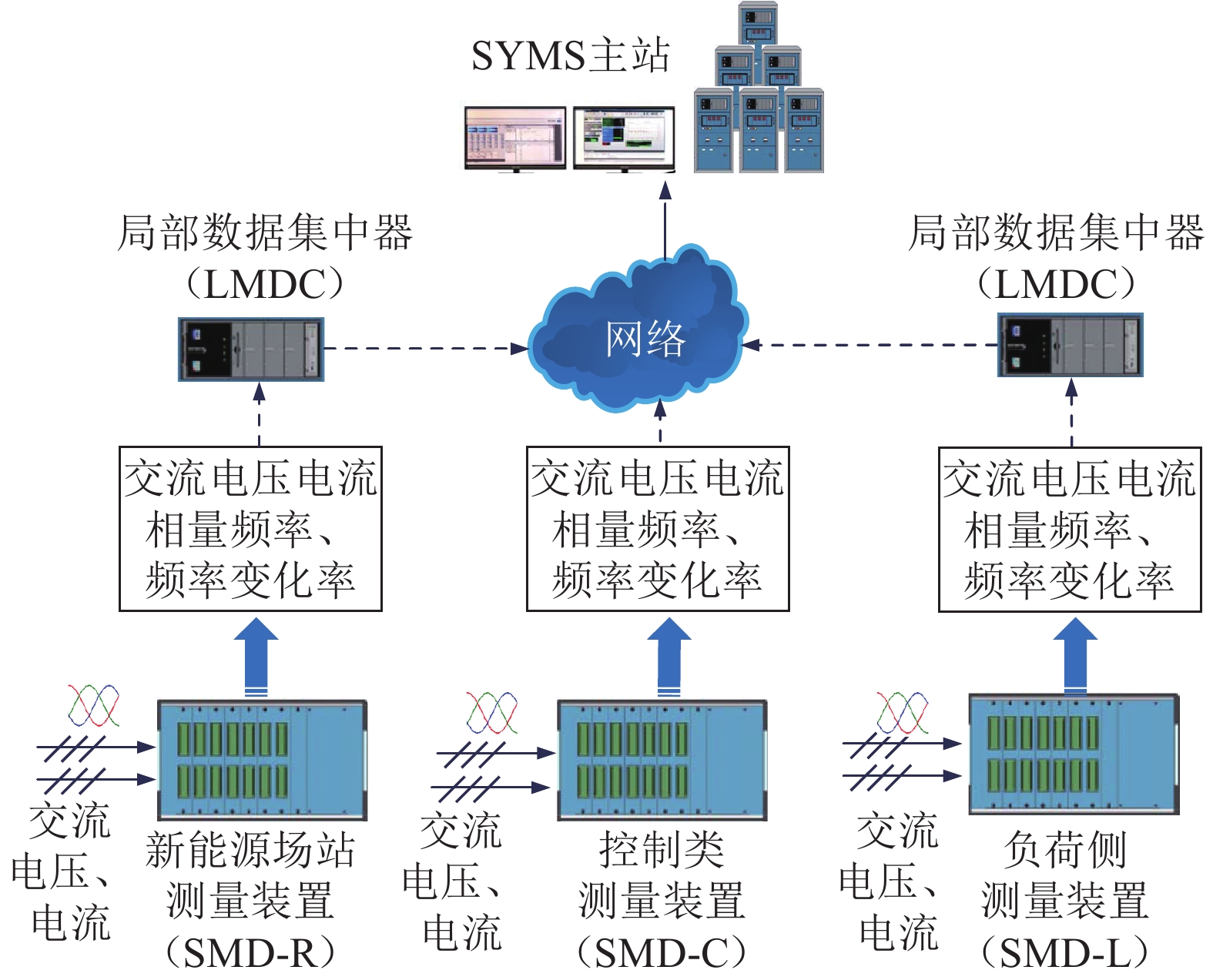 图 1 SYMS系统整体架构图Fig. 1 Overall architecture diagram of SYMS
图 1 SYMS系统整体架构图Fig. 1 Overall architecture diagram of SYMS 下载:
全尺寸图片
下载:
全尺寸图片
从数据特征来看,SYMS主站所接收的数据主要可以分为基波、谐波、间谐波数据3种,表1介绍了不同SMD装置的测量数据特征。由于基波数据中相量及模拟量等关键量信息会在1 s内发生显著变化,为了满足主站数据的数据分析需求,基波数据采取50或100 Hz的上传速率,但谐波数据、间谐波数据中各量幅值及相位在1 s内变化较小,上传速率传输往往采用1 Hz。对于主站前置数据平台而言,为避免消息阻塞,保障主站稳定性,需要在分布式框架下开发归一化的处理方法,以保证对SYMS系统多源异类数据进行实时解析与处理。
表 1 不同SMD设备的测量数据特征Table 1 Data characteristics of different SMDs不同SMD 数据类型 测量频带/Hz 上传频率/Hz SMD-R 基波 20~80 50 间谐波 0~20、80~100 1 SMD-C 基波 48~52 100 SMD-L 基波 45~55 50 谐波 0~45、55~100 1 间谐波 2次~50次谐波 1 1.2 适用于SYMS主站的多源异类数据适配器设计
在数据通过公网上传时,SYMS主站侧采用开源的电力相量数据集中器OpenPDC对外开放固定端口作为TCP服务端,而每台SMD装置作为TCP客户端。两端通过解析图2的装置配置帧,建立起实时数据通道,随后主站侧将收到来自现场的基波、谐波、间谐波数据[16]。
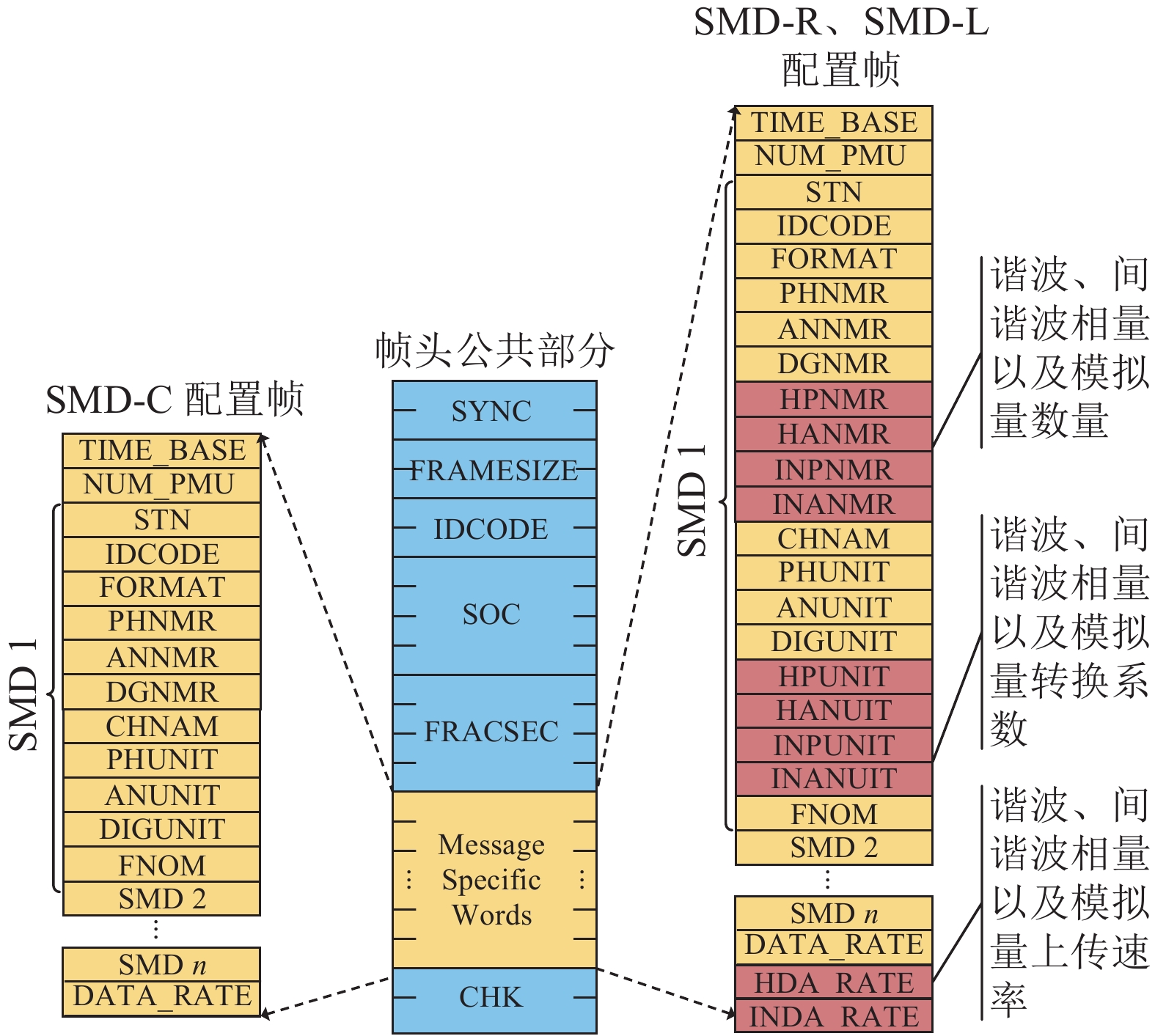 图 2 SMD装置配置帧结构图Fig. 2 Structure diagram of SMD configuration下载:
全尺寸图片
图 2 SMD装置配置帧结构图Fig. 2 Structure diagram of SMD configuration下载:
全尺寸图片
在每个数据通道中,不同上传速率、数据包大小不同的数据帧被发往主站对应端口,数据帧的格式如图3所示,主要包括基波数据帧、谐波数据帧、间谐波数据帧。
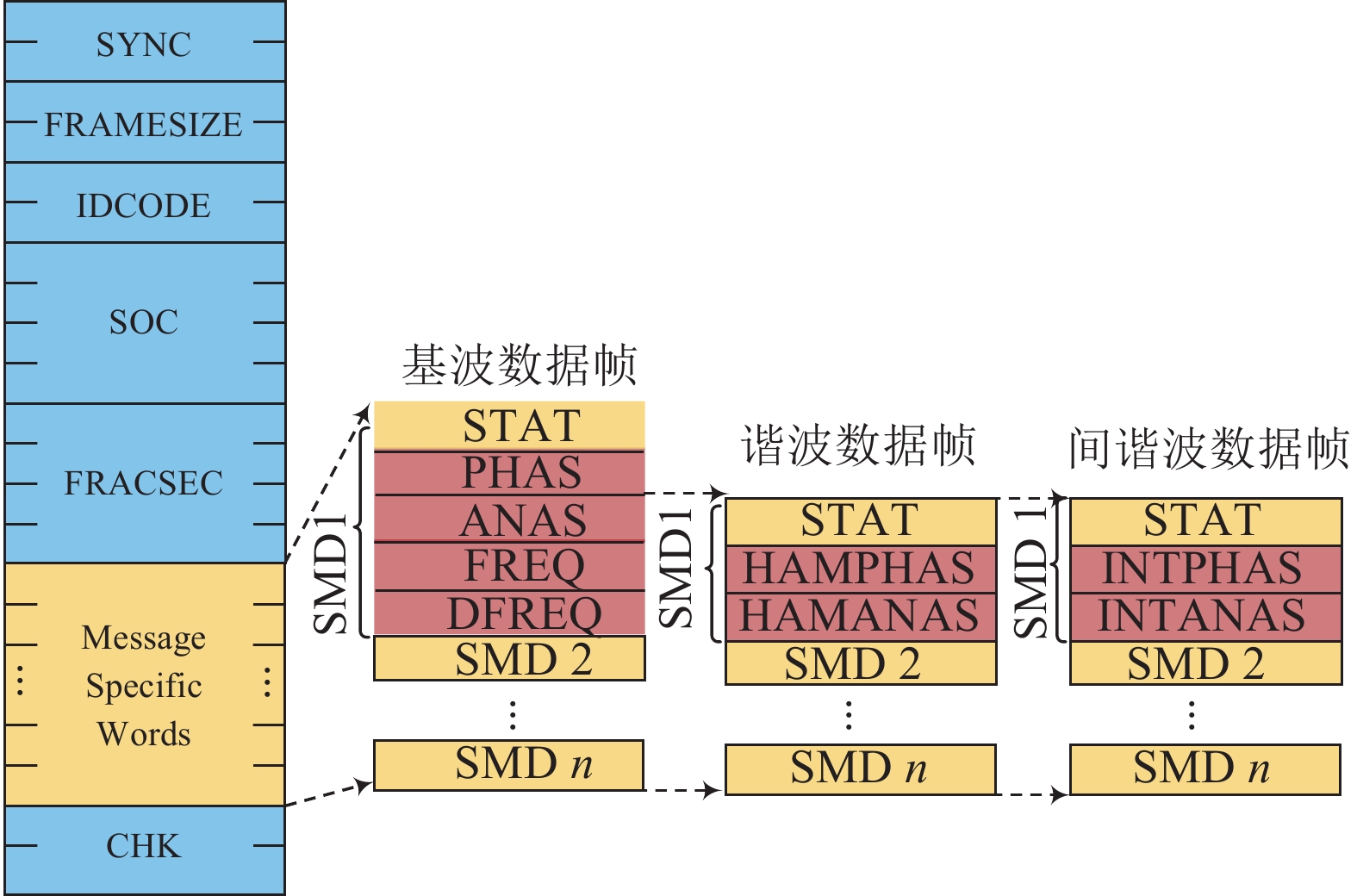 图 3 SMD装置数据帧结构图Fig. 3 Structure diagram of SMD data frame下载:
全尺寸图片
图 3 SMD装置数据帧结构图Fig. 3 Structure diagram of SMD data frame下载:
全尺寸图片
OpenPDC需要对上述多类型测量数据帧进行处理,因此设计了一种适用于SYMS主站的多源异类数据适配器,实现了多源异类数据的归一化管理,由程序逻辑图4可见,在确认建立TCP通信后,适配器通过分析帧结构判断数据帧类型,对相量信息开展进一步处理。
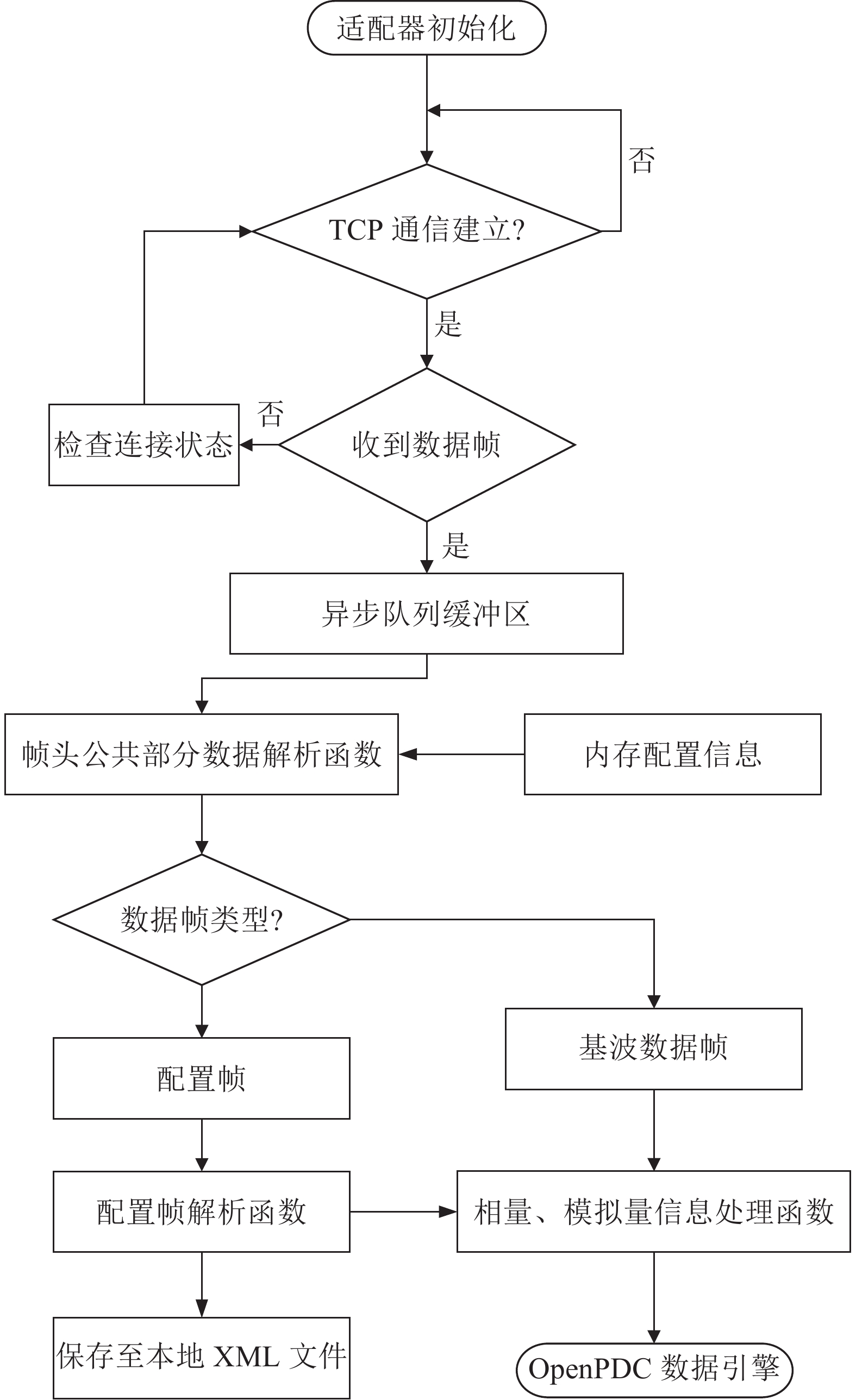 图 4 适用于SYMS的多源异类数据适配器程序流程图Fig. 4 Flowchart of multisource heterogeneous data adapter program for SYMS下载:
全尺寸图片
图 4 适用于SYMS的多源异类数据适配器程序流程图Fig. 4 Flowchart of multisource heterogeneous data adapter program for SYMS下载:
全尺寸图片
实时数据帧在进入实时通道后,从TCP服务端端口广播输出,适配器通过调用OpenPDC中通信端口建立TCP客户端,主动对接前端的实时数据通道,经过3次握手后,将实时数据帧接入适配器中,适配器会将不同类型的数据帧导入异步队列缓冲区,等待闲置数据处理线程提取,其具体流程示意如图5所示。
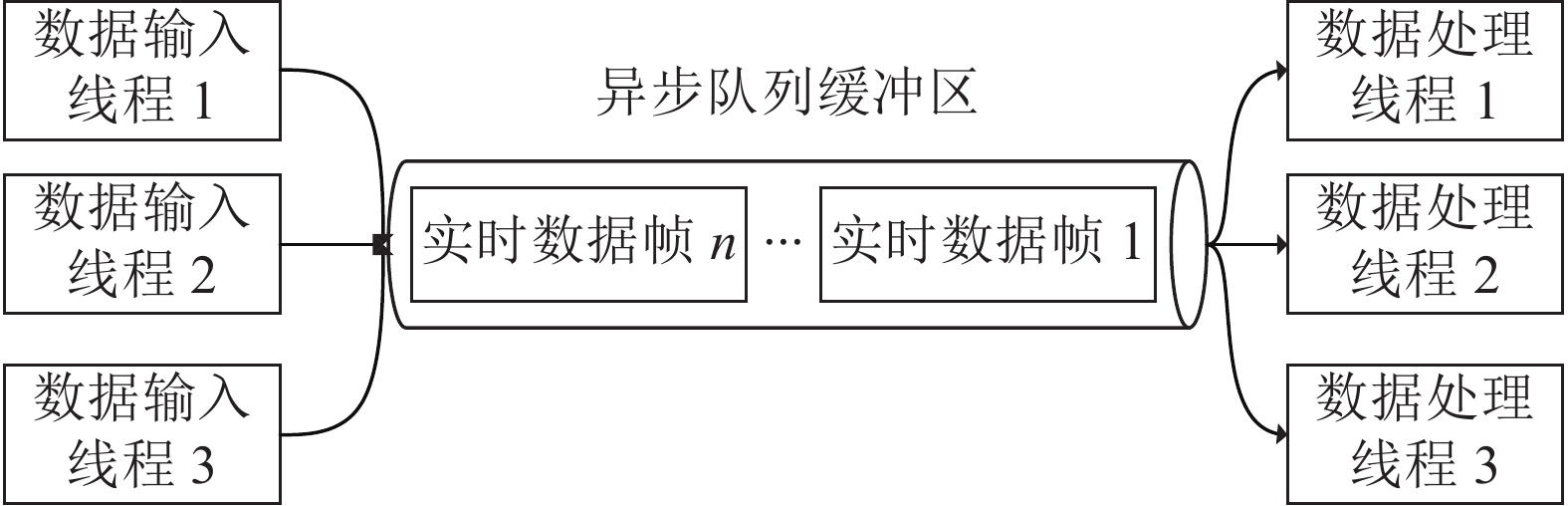 图 5 异步队列缓冲区Fig. 5 Asynchronous queue buffer下载:
全尺寸图片
图 5 异步队列缓冲区Fig. 5 Asynchronous queue buffer下载:
全尺寸图片
在输入端,同一时间断面下允许了多个线程执行SMD实时数据帧的入队操作,以此提高适配器的并发处理能力;在输出端,SMD的实时数据帧能够被多个线程异步处理,计算处理速度大幅度提高,但这样做的缺点在于处理的数据帧顺序会被打乱,后续需重新进行排序。
异步队列缓冲区中的数据帧包括配置帧、基波数据帧、谐波数据帧、间谐波数据帧。根据数据情况,实现了帧头公共部分的解析方法,并开启多线程操作,可获取数据帧的类型、时间戳、大小等关键信息。
帧头公共部分数据解析方法包括3个变量:内存中的配置信息、数据帧的字节数据、起始位。内存中的配置信息由本地文件读取,其中TIME_BASE字段作为秒等分数时间的分辨率。在开始处理时,起始位StartIndex置零,从数据帧字节数组头部开始赋值操作。根据相量数据传输协议,不同数据信息变量所占字节数不同,如SYNC帧包含2字节,IDCODE包含8字节。在完成一个变量的解析后,将起始位变量加上偏移位Offset,并依次执行至字节数组末端,对帧头整体解析过程可参考图6。
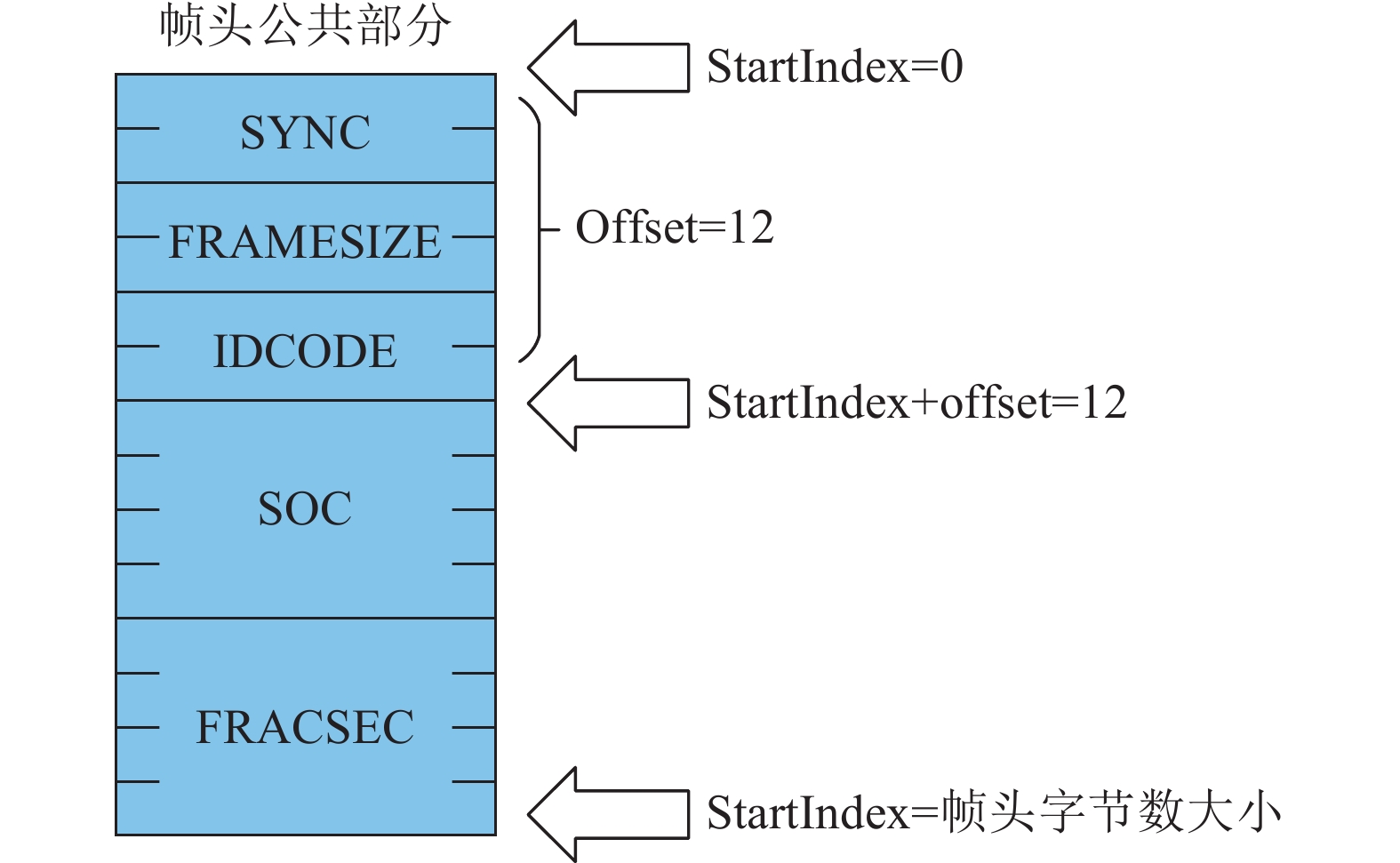 图 6 帧头公共部分解析方法Fig. 6 Parsing method of the frame header’s public part下载:
全尺寸图片
图 6 帧头公共部分解析方法Fig. 6 Parsing method of the frame header’s public part下载:
全尺寸图片
对帧头公共部分解析获取帧类型后,调用解析函数进行下一步处理。图7为识别到基波数据帧时的多线程处理流程图。由图7可见,为提高实时处理速度,基于Offset情况将数据帧字节数组拆分为头帧、中间帧和尾帧,开启三线程分别处理,并返回解析后字节数,最终验证总解析字节数等于FRAMESIZE时,表示整个数据帧处理完成。
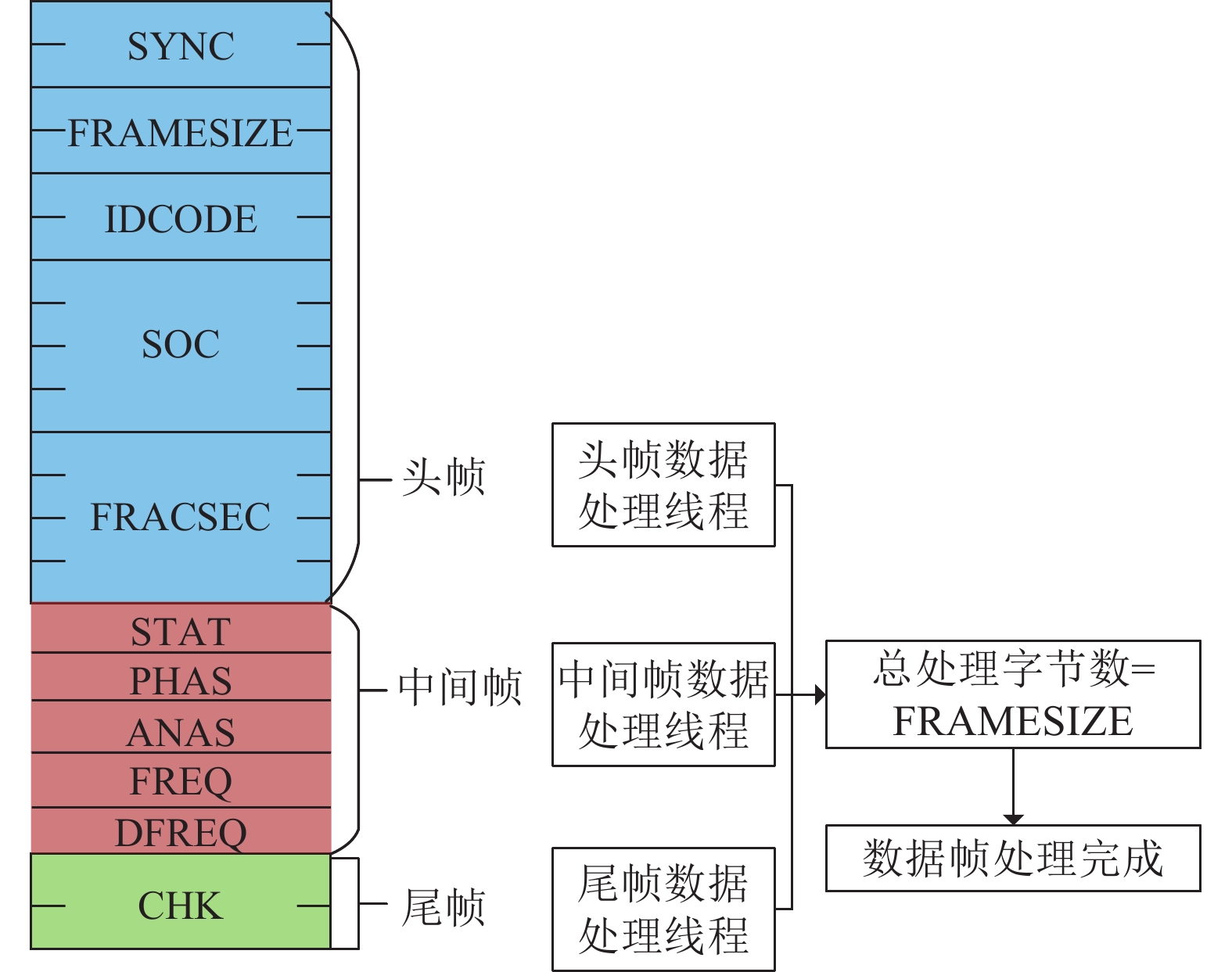 图 7 基波数据帧多线程处理流程图Fig. 7 Flow chart of multi-thread processing of fundamental wave data frame下载:
全尺寸图片
图 7 基波数据帧多线程处理流程图Fig. 7 Flow chart of multi-thread processing of fundamental wave data frame下载:
全尺寸图片
对于基波、谐波、间谐波的数据帧,中间帧数据处理线程会根据相关配置信息,对相量、模拟量进行计算处理,得到转换过后的实际数值,并同帧头线程处理线程中解析出的时间戳组成对应测量数据的键值对(Key-Value)形式,即时间戳为Key,测量数据的值为Value。对于不同类型的数据帧,其中的测量量最终都转换为这样的键值对形式,经过OpenPDC数据引擎对时、排序后整合为实时数据流。该数据流一部分存入分布式数据库持久化;另一部分,经由消息队列发送至主站的分布式流处理系统,这一部分的实现将在第2节介绍。
2. SYMS分布式主站流式计算平台
2.1 SYMS主站流式计算框架
依靠近年来逐步投入运行的上百台SMD装置,SYMS主站已经接收了全国各地的大规模同步相量历史数据。通过对历史数据的整理与分析,包括坏数据识别与修复、状态估计、扰动初判、扰动识别与定位等多种算法已经被开发,这对电力电子化的电力系统的状态感知与动态过程分析具有重要意义。目前,SYMS主站已将相关算法部署为串联的多个功能,通过对数据的实时分析实现对新型电力系统的运行状态监测。然而受到系统架构、计算资源、多语言适配问题的限制,主站应用平台的实时性较差,亟需利用分布式框架对平台重构,提升运算效果。
Storm是由Twitter开发,Apache基金会开源的一个分布式、高容错的实时流式计算框架[17],其运算集群包括一个主节点和多个工作节点,集群整体结构见图8。其中:主节点分发代码、管理集群,其借助分布式协调技术Apache Zookeeper实时感知工作节点运行状态,进行统一管理,同步每台机器的工作进展,以解决分布式计算中的一致性问题。工作节点则对整合后的大规模实时数据集进行流式处理,并将本机中各个计算任务的执行情况反馈给主节点。Storm将计算任务抽象为有向无环图结构的拓扑,主节点利用Nimbus守护进程分析拓扑,并将拓扑中的任务向下分配,每个工作节点将开展多个进程以执行多个不同的计算任务。
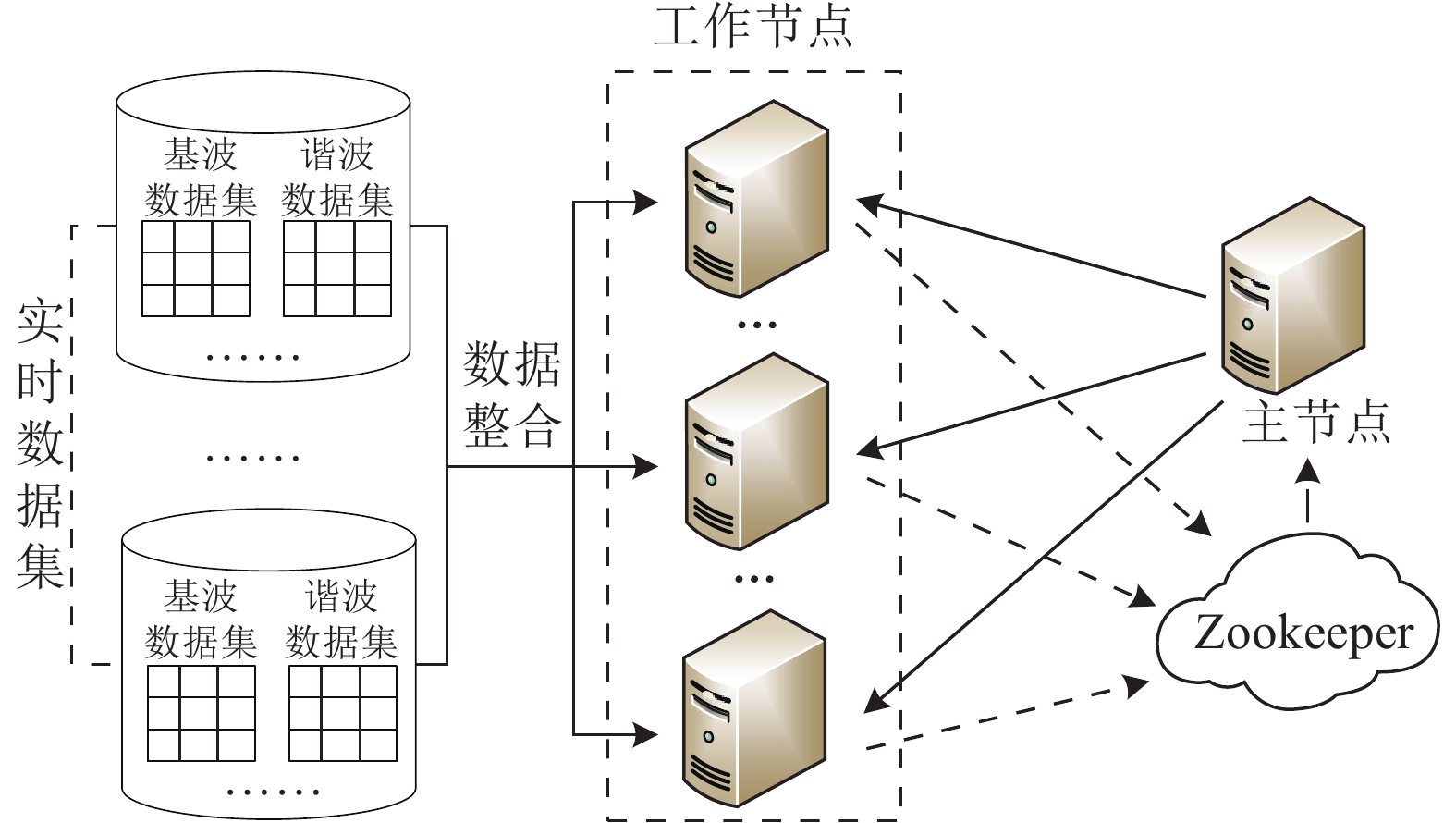 图 8 Storm集群外部框架图Fig. 8 Framework diagram of Storm cluster下载:
全尺寸图片
图 8 Storm集群外部框架图Fig. 8 Framework diagram of Storm cluster下载:
全尺寸图片
Storm的拓扑包括Spout和Bolt两个抽象概念,它们对元组(tuple)格式的数据进行操作和转换。元组是一个包含命名的值列表,可以包含多种数据类型。Spout可以持续读取数据,并将其转化为元组发送给下游的Bolt。这样源源不断传递的元组就被抽象为流(Stream)。Bolt中封装了对数据处理的逻辑,在处理完毕后,会将结果发送至下游Bolt,根据事件分析结果展开下一级运算。为将SYMS主站应用平台与Storm结合,需将平台内部运算逻辑映射至Storm拓扑中。
图9为基于Storm设计的SYMS主站应用平台运行逻辑图。由图9可见:主站前置数据平台在对实时相量数据接收和解析后,一方面,将数据持久化存储;另一方面,将数据发送至应用平台展开分析。通过基于经验模态分解的扰动初判算法,系统将对每台装置的频率数据展开分析,如果判断发生扰动,系统将提取该装置附近多台装置在相同时间段的数据展开协同分析,判断该扰动是否为坏数据导致的误判。如果确为扰动,系统将通过分析多设备数据对扰动进行分类与定位。将应用平台运行逻辑与Storm架构映射可以看出,主站前置数据平台与分布式数据库向应用平台发送数据的过程可被映射为Spout,传递的相量数据可被映射为tuple,数据的接收与算法分析过程可被映射为Bolt,事件识别的结果也可被映射为tuple,传递给下游的Bolt运算。
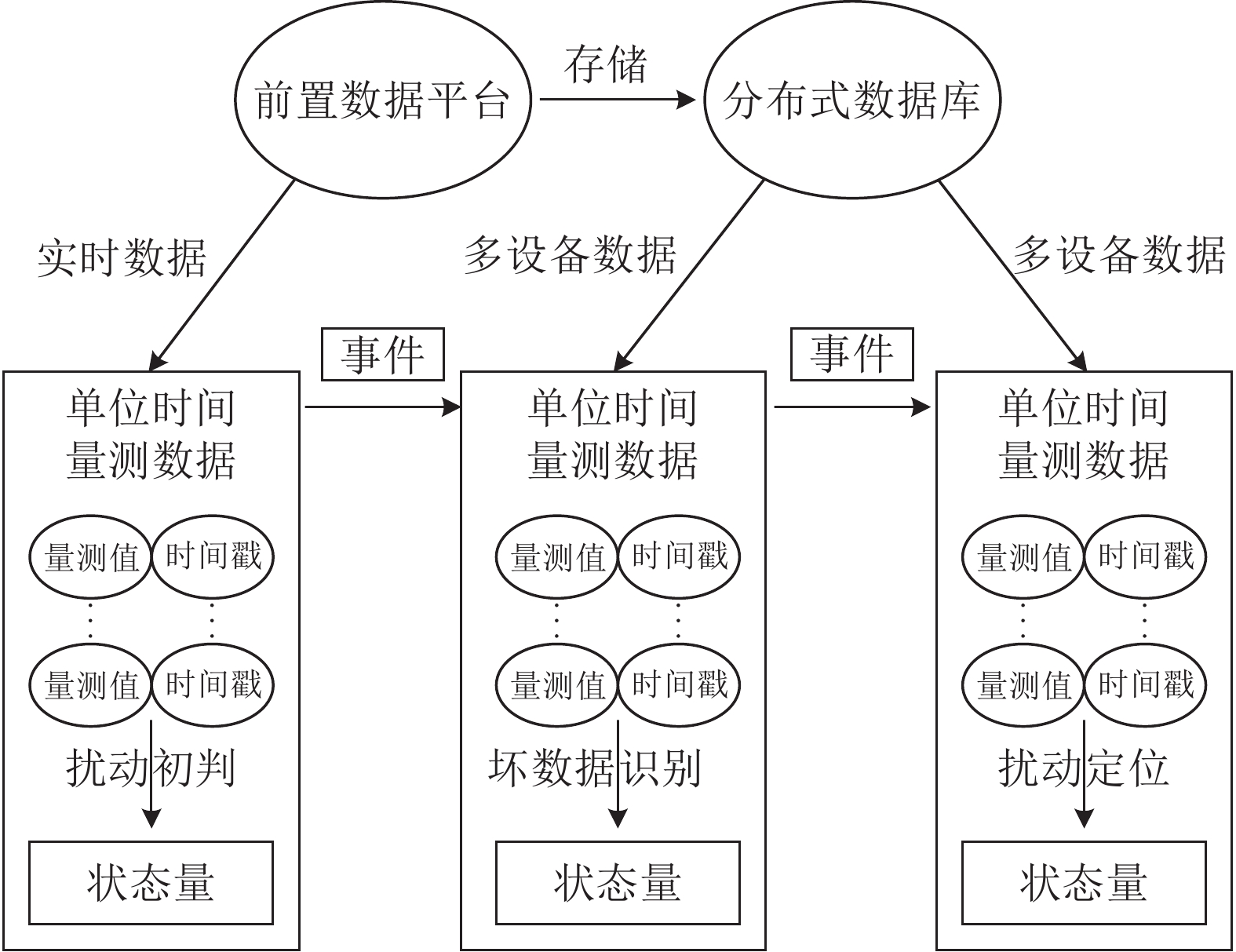 图 9 SYMS主站应用平台运行逻辑图Fig. 9 Logic diagram of SYMS master station’s application platform下载:
全尺寸图片
图 9 SYMS主站应用平台运行逻辑图Fig. 9 Logic diagram of SYMS master station’s application platform下载:
全尺寸图片
Spout和Bolt的执行单位是线程,因此,对于不同功能的Bolt,可以根据负载轻重为其设置不同的并行度(线程数),以便于对每个任务进行资源分配和管理。对于单个Bolt而言,其对于数据处理的逻辑是相同的,但是由于所处线程不同,则对Spout订阅关系不同,所以进行操作的数据并不相同。图10给出了Storm拓扑与集群对应关系。由图10可见,通过Spout在上游多线程接入多设备上传数据,Bolt端就可以用一套逻辑处理全部数据。在主节点,将拓扑提交至Storm集群后,主节点通过Nimbus进程与工作节点的Supervisor进程通信,根据拓扑将计算任务分配至工作节点的不同JVM的不同线程执行。
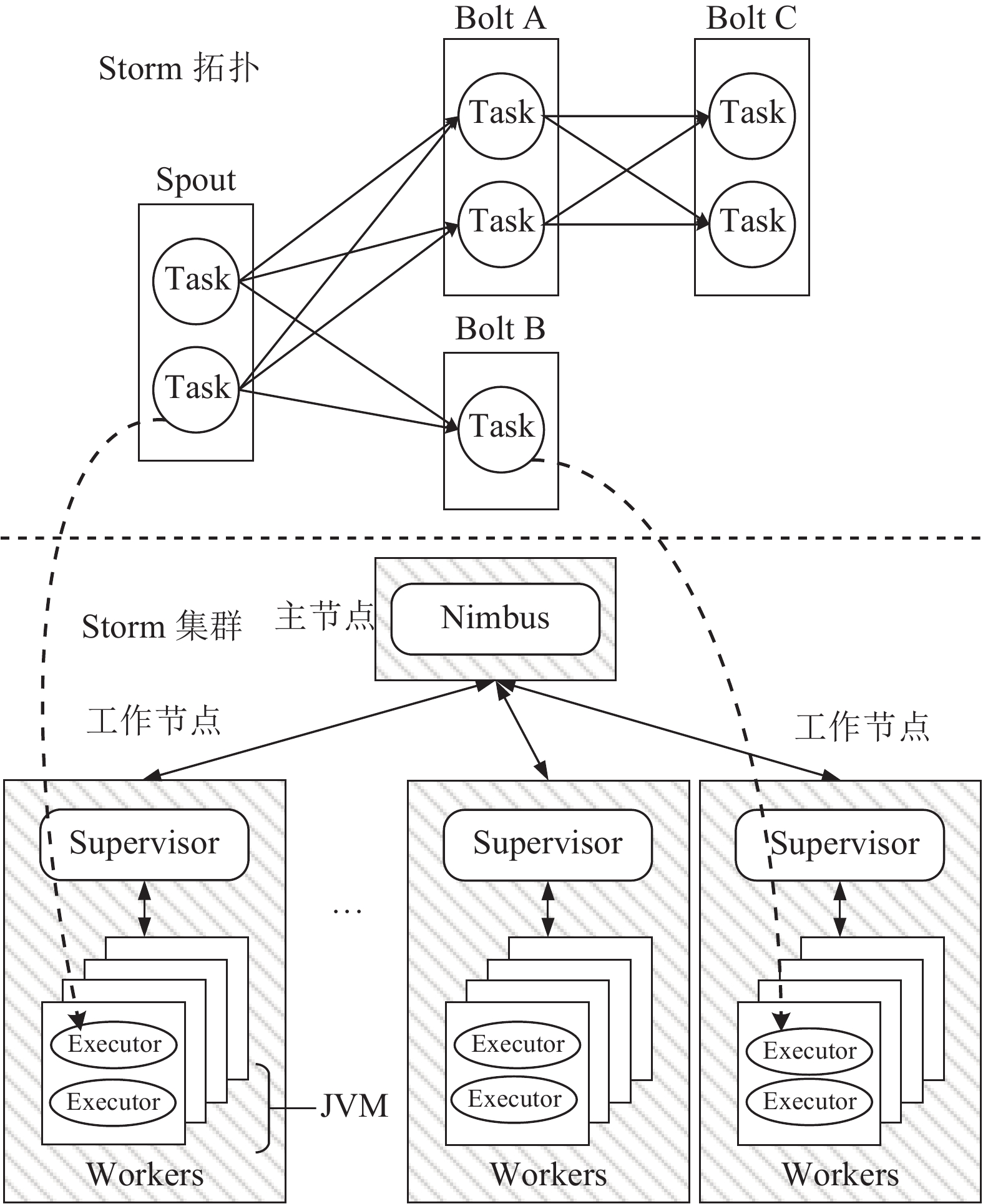 图 10 Storm拓扑与集群对应关系Fig. 10 Correspondence of Storm topology and Storm cluster下载:
全尺寸图片
图 10 Storm拓扑与集群对应关系Fig. 10 Correspondence of Storm topology and Storm cluster下载:
全尺寸图片
通过将任务分散至不同机器并进行细颗粒度的管理,Storm分布式计算在提高系统容错性的同时,将所有计算资源整合起来充分利用,避免了单机计算的阻塞问题。此外,Storm集群机器数量并不是固定的,可根据拓扑计算压力对集群规模进行调整,实现了计算资源的自由扩展,这极大降低了主站的运行成本。
2.2 基于KafkaSpout的异步通信方法
从主站的角度看,Spout相当于前置数据接收平台与数据处理平台之间的一个数据适配器。由于SMD装置的相量测量数据类型较多,为了降低耦合性,作者利用Apache Kafka消息队列将多源异构数据分群,根据后续算法的要求通过图11流程来配置Spout的读取方式,即前置服务平台中的适配器在每次解析完毕后,将数据上传至Kafka集群缓存,由Kafka向Storm集群提供可靠持续的数据流。
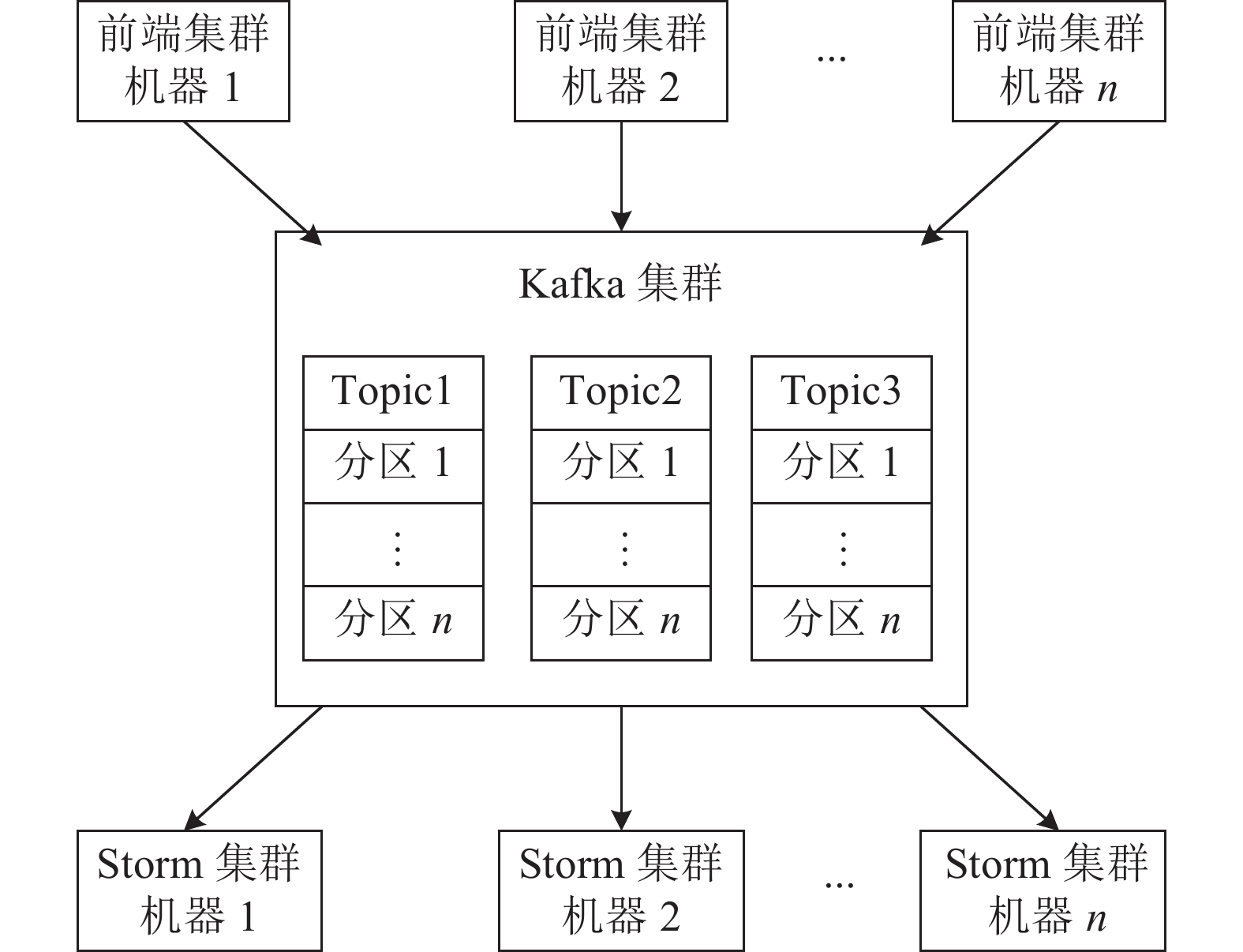 图 11 Kafka集群实现异步通信的框架图Fig. 11 Framework diagram of asynchronous communication using Kafka cluster下载:
全尺寸图片
图 11 Kafka集群实现异步通信的框架图Fig. 11 Framework diagram of asynchronous communication using Kafka cluster下载:
全尺寸图片
Apache Kafka是一个高可扩展性的分布式消息队列[18],它为处理实时数据提供了一个统一、高通量、低延时的平台,一方面,避免了前后端集群点与点的直接通信,将消息生产者和消费者解耦;另一方面,由于任何实时处理系统的处理速度都小于数据产生的速度,因此新产生的数据需要被Kafka队列缓存,等待Spout读取,达到了异步通信效果。
为了提高读取效率,Kafka在内部实现了多点、分区、多副本的日志维护服务。Kafka集群会管理按主题(topic)区分的消息,每个topic下的消息由若干物理分区组成,每个分区是有序、不可变的消息序列,每个序列可以被连续地追加消息。
在实际工作中,前置数据处理集群相当于Kafka消息生产者,可同时并行写入多设备数据,数据将以时序形式顺序存储在Kafka集群的多个物理分区中。Storm拓扑中的Spout相当于Kafka消息消费者。令Kafka服务器根据SMD数据类型(如频率、电压等)来维护topic,使得每个topic记录着多个设备同一数据量的集合,每一台实际设备的数据对应一个Kafka物理分区。
以扰动初判算法为例,其对SMD-L 3 min内的频率量进行分析,并将初判后的结果送至下一级计算。前置系统在为每台SMD-L建立实时数据通道后,会实时将其中的频率数据顺序写入Kafka集群中频率主题下不同编号的物理分区。Spout端开启多线程,每一个线程对应读取一个分区的频率数据,并将键–值对形式的数据转换为元组格式[topic,partition,offset,key,value],传递给下一级Bolt,整个过程的延时只有几毫秒,充分保证了大规模数据后续的实时分析[19-20]。
2.3 Bolt的多语言设计与开发
Bolt作为Storm集群中开展实时分析的模块,其实现方式直接决定了系统的处理性能好坏。本节将从功能搭载与算法调用方式两方面完成对Bolt代码结构的设计。
与传统大数据框架相同,Storm的Bolt逻辑也是用Java实现。但在电力系统中,借助离线数据研究的算法往往是基于MATLAB、Python、C++等平台开发。如何在同一个框架下搭载多语言算法,并保障其计算效率,成为了首先要解决的问题。
Storm的拓扑是基于跨语言的远程服务调用框架Thrift开发的,借助Shell类和Multilang协议实现了多语言支持。Storm通过Shell类中开发的IBolt接口,向外部进程传递JSON编码结构的标准输入输出流,在子进程中异步执行其他脚本程序。
然而,以MATLAB为主的电力系统分析算法在借助多语言协议执行的过程中,处理延时普遍较高。主要问题包括:1)子进程中定时调用算法时需要启动MATLAB进行计算,其启动过程往往需要几秒至十几秒不等;2)如果一直在后端运行MATLAB进程,则会浪费较多内存资源;3)每台虚拟机都需安装MATLAB程序,这将浪费较多硬盘资源。
针对这一情况,本文设计了一种预编译–Jar封装的调用方法。首先,借助MATLAB Library Compiler,将算法所在的m文件进行Java混编,封装为Jar包。其次,在Bolt编程实现时,将算法输入参数构造为MWNumericArray,通过MATLAB编译环境(MATLAB compiler runtime,MCR),整个Bolt运行过程可以在一个Java虚拟机中实现,大幅缩短了含MATLAB算法Bolt的处理延时。在此方法下,Storm集群中每台计算机只需额外安装MCR环境,MCR本质上是一组标准动态链接库,因此相比于安装MATLAB,每台机器可以节约20 GB的硬盘空间,这也将提高Storm集群的性能。
2.4 适用于SYMS的算法调用拓扑设计
传统分布式实时系统的处理对象往往是单条消息,但电力系统中的算法往往是针对一个时间窗内的数据展开分析,且不同算法时间窗存在较大差异。针对SYMS系统特点,设计了触发式调用拓扑结构,保证每个算法都可以被可靠调用。
以扰动初判算法为例,其每次分析单台设备3 min内连续的9 000个频率数据,将扰动初判算法按第2.3节所述的方法布置在多线程运行的Bolt内部,即可实时对多台设备进行扰动初判。
位于拓扑前端的KafkaSpout会顺序读取每个分区的频率数据,并以元组的形式向外发射。由于元组中partition位置对应的数值不同,因此让Bolt端根据字段名进行流分组,不同线程订阅不同的流。Bolt端会提取元组中的时间戳和频率数据分别存入动态数组中。在数据采集时间达到算法窗长时,TriggerSpout会发送此时刻对应的时间戳,Bolt在接收后该触发信号后,查找该时间戳在动态数组中的坐标,提取出在这之前的9 000个数据进行分析。用圆圈代表执行相同功能的不同线程,则整体拓扑概念如图12所示,实际运行时扰动初判算法将在Storm集群中不同机器的不同线程中展开分布式运算。
 图 12 利用触发信号控制算法调用的拓扑概念图Fig. 12 Conceptual diagram of topology using trigger signals to control algorithm calls下载:
全尺寸图片
图 12 利用触发信号控制算法调用的拓扑概念图Fig. 12 Conceptual diagram of topology using trigger signals to control algorithm calls下载:
全尺寸图片
相比于传统时间窗的处理操作,触发式拓扑具有以下优点:1)TriggerSpout针对每个线程分别发射触发时间信号,使每个算法的调用错峰进行,可以极大降低CPU占用;2)同一台设备的数据可以发送给多个Bolt线程,触发信号可以轮流发送给多个线程,这使得一台设备的数据分析可以由多个线程并行计算,这是时间窗管理方法难以实现的;3)TriggerSpout中的ack方法可以跟踪Bolt运行情况,如果算法执行失败会返回fail。在一段时间后,触发信号将被重新发送执行,而不需重新向KafkaSpout端申请重新读数,这将提高系统的容错性。
针对不同时间窗长的算法,只需为其设计对应时间间隔的TriggerSpout,即可实现在Storm中的可靠调用。此外,Storm集群中计算资源占用率的提高普遍是因为算法的调用执行,后续在对系统进行负载均衡时,可以对TriggerSpout进行再开发,使其根据集群负载情况修改触发信号发射方式。
3. 分布式SYMS主站的实现及测试
3.1 基于HAProxy的前置负载均衡集群
现有主站架构中前置系统采用单机式部署,在处理海量数据时容易造成性能瓶颈,且单节点故障后SYMS主站易陷入停滞。通过将服务器构建成集群工作方式,分布式的前置系统提高了前置数据服务的扩展性与并发处理能力。为对集群中各节点负载量合理分配,在集群中加入了软件负载均衡HAProxy作为负载均衡调度器,将SMD装置的请求连接分发,并与负责前置应用服务的OpenPDC集群进行交互。通过在前置负载均衡集群配置适用于应用场景的负载均衡算法,可以合理分发SMD装置实时上传的海量数据,缓解前置应用服务器的负载压力。同时加入基于Keepalived技术的备用节点,保证高可用性[21-22],前置服务器中的负载均衡架构可参考图13。
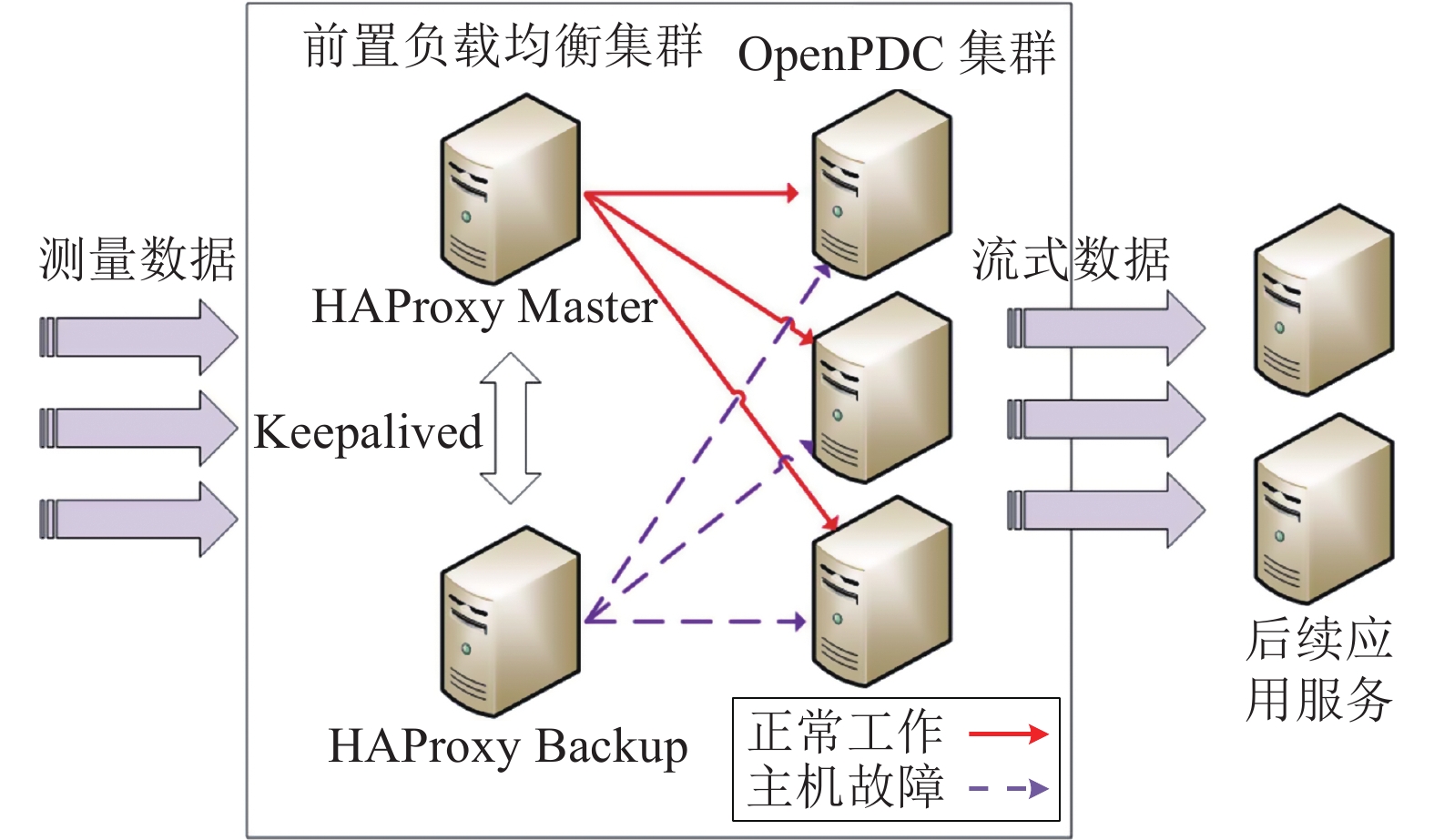 图 13 前置负载均衡集群架构图Fig. 13 Front load balancing cluster architecture diagram下载:
全尺寸图片
图 13 前置负载均衡集群架构图Fig. 13 Front load balancing cluster architecture diagram下载:
全尺寸图片
负载均衡调度器是负载均衡集群中的核心部分,它起到了对SMD装置的请求连接分发及与前置应用服务的交互作用,通过配置适用于应用场景的负载均衡算法,可以实现SMD装置海量数据的分发,使得前置应用服务器的负载压力得到合理的分配;除此之外,利用负载均衡调度器能够实现服务器节点的增减,可显著提升系统的扩展能力。根据HAProxy的工作原理,并结合SMD装置的通信特点,将负载均衡调度器以TCP4层负载均衡工作方式运行,负载均衡算法采用内置的最小连接数算法实现。
在SYMS主站中,前置负载均衡集群由负载均衡调度器及第1.2节中提出的SMD装置数据适配器组成。该集群已在虚拟化私有云平台中搭建完毕,并在3节点集群下进行了一系列测试。
首先,进行了前置负载均衡集群的并发连接测试。通过设计模拟SMD装置脚本程序,使程序可以与实际硬件装置连接,根据所设模拟装置数量复制数据帧报文及配置报文,进而连接前置负载均衡集群,进行并发连接测试,集群中各节点分配的连接情况如图14所示。
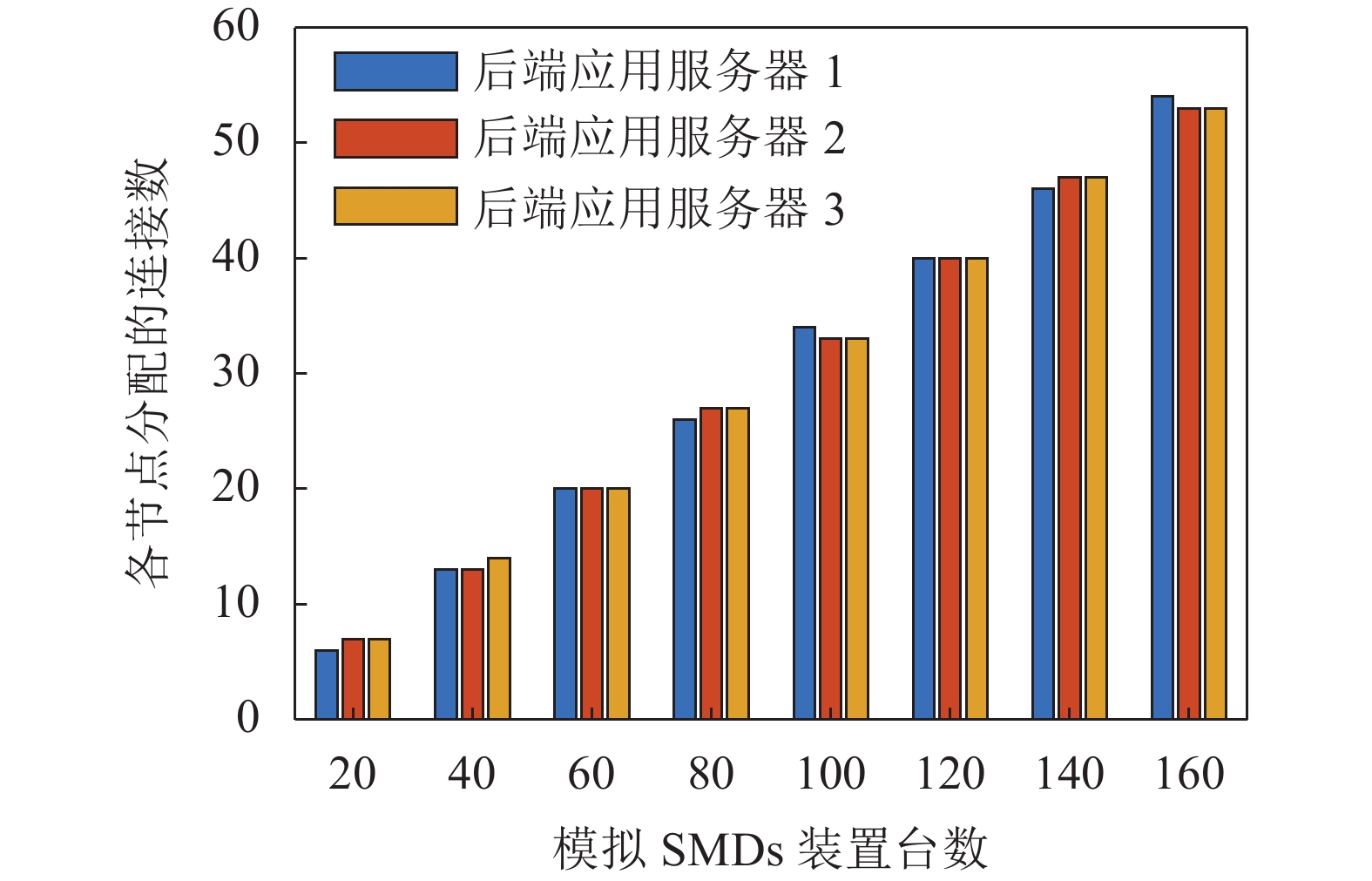 图 14 前置负载均衡集群各节点分配连接数Fig. 14 Number of connections allocated to each node of the front load balancing cluster下载:
全尺寸图片
图 14 前置负载均衡集群各节点分配连接数Fig. 14 Number of connections allocated to each node of the front load balancing cluster下载:
全尺寸图片
由图14结果可知,在面对不同规模SMD装置时,前置负载均衡集群实现了对SMD装置的负载分配,在负载均衡算法的支持下,保证了前置应用服务器节点分配到的负载量尽可能地平均。
其次,也开展了单机与集群的性能对比测试。将单机资源进行纵向扩展,集群资源横向扩展,令扩展后的硬件资源相同,通过对比各服务器节点的负载情况判断性能优劣,图15展示了模拟装置台数增加时,单机与集群处理数据时的负载量对比情况。
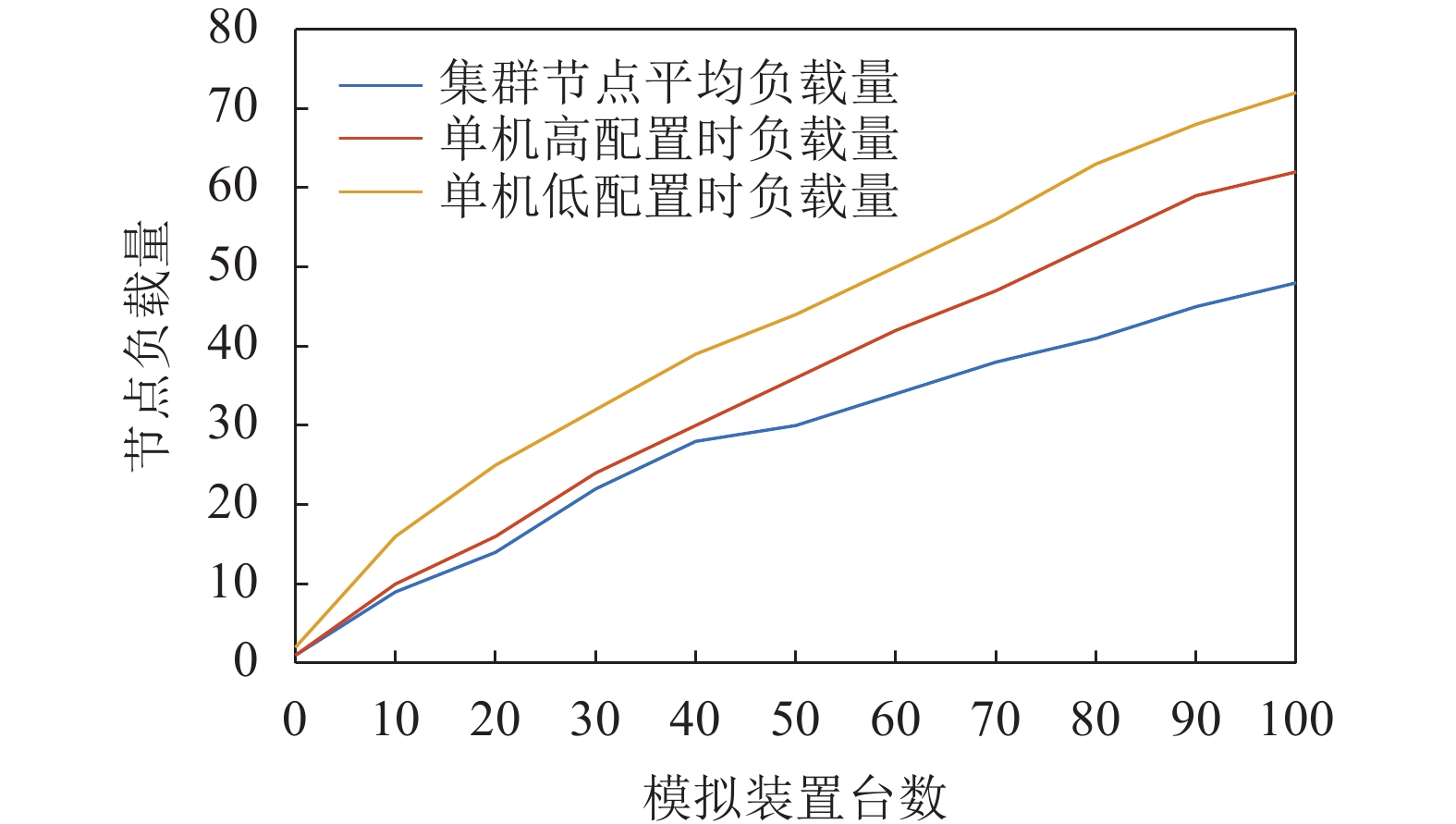 图 15 单机与集群节点负载量对比Fig. 15 Comparison of the load of a single machine and a cluster node下载:
全尺寸图片
图 15 单机与集群节点负载量对比Fig. 15 Comparison of the load of a single machine and a cluster node下载:
全尺寸图片
从图15测试结果可知,随着装置数量增加,SYMS主站前置机群以及单机的节点负载量差距越来越大,且在性能上集群在100台装置左右时,较单机优化了20%左右,整体呈现上升趋势。这意味着在后续系统发展过程中,前置负载均衡集群的优势会越来越明显。
3.2 实时分布式处理系统Storm的实现
为了测试分布式处理系统Storm在SYMS主站中的搭载效果,对本文所述系统进行了云环境测试。在主站的虚拟化私有云平台中,选择3台配置相同的虚拟机搭建Kafka集群,5台配置相同的虚拟机搭建Storm集群,其硬件配置及软件环境情况如表2所示。
表 2 虚拟机硬件参数及实验平台Table 2 Virtual machine hardware parameters and experimental platform虚拟机类型 虚拟CPU
个数内存/GB 操作系统 实验平台 Kafka虚拟机 2 8 CentOS7 Kafka2.11、
Zookeeper3.6.3Storm虚拟机 2 8 CentOS7 Storm1.2.3、
Zookeeper3.6.3、
MCR 9.2在实际测试时,Kafka中频率主题的每个分区会在每20 ms写入一次数据,KafkaSpout会持续监听,并将数据发送至Storm集群内部处理。为了对比测试效果,将一台计算资源与Storm集群总计算资源相等的单台虚拟机以Java多线程的方式执行相同的功能,每隔2 min调用一次扰动初判算法。
图16、17是单机多线程运算与Storm运算时单台机器的CPU占用情况。由图16、17可以看出:在程序初始化配置后,在不调用算法时,单机与集群处理的CPU资源占用较少,此时只有接收数据操作,性能差异较小。但每隔2 min接收到触发信号,展开算法调用后,此时单机与集群的CPU占用率都大幅上升。不同的是,集群中CPU占用率尖峰较窄,高CPU占用率的持续时间明显较短,这意味着扰动初判算法在迅速计算完毕后,可以及时将事件识别结果发送至下一级。而在单机运行时,机器会进行长时间运算,且相比于Storm集群计算,单机计算在向下一级发送事件结果的平均耗时较长。
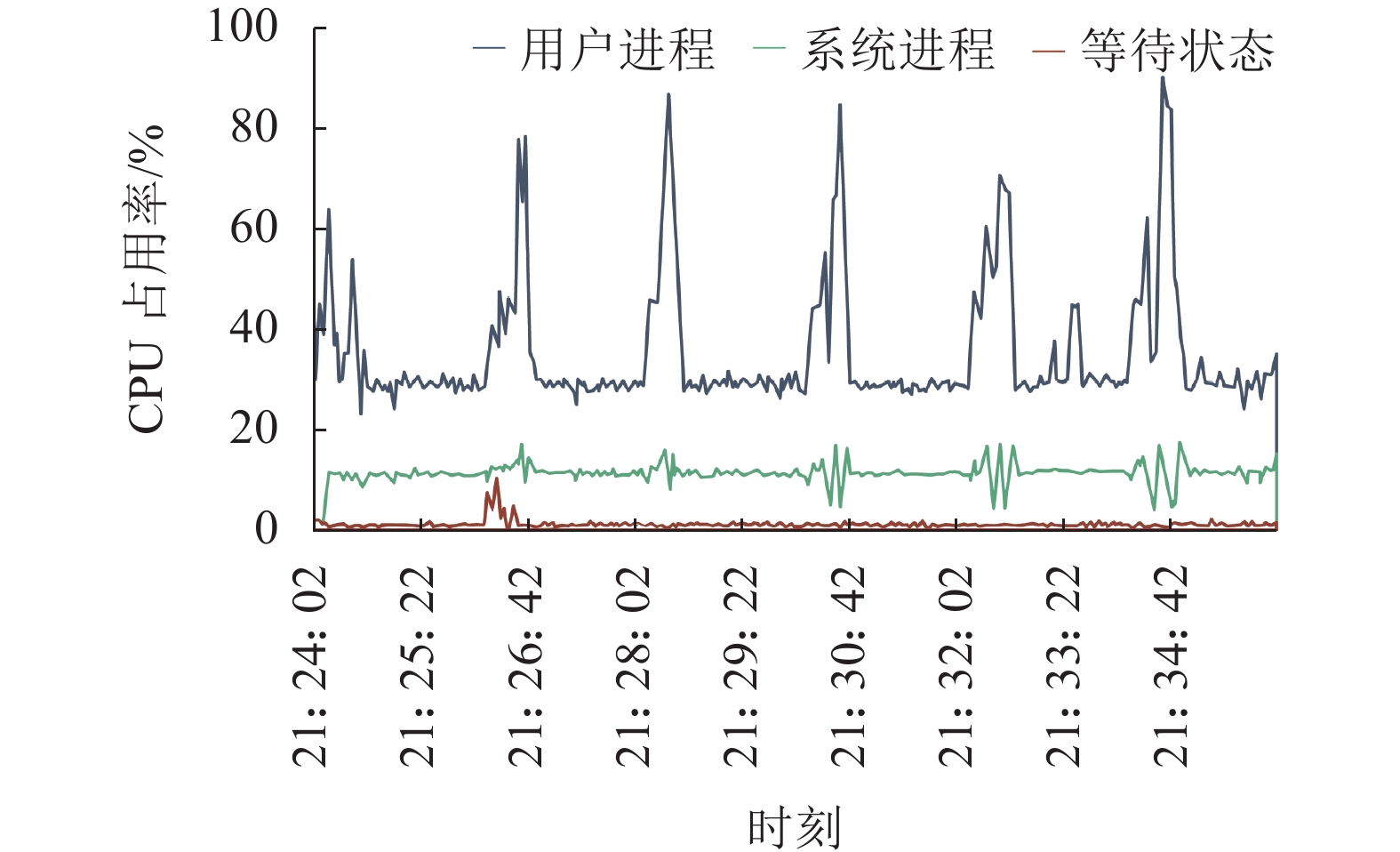 图 16 5台SMD设备实验中单机CPU占用情况Fig. 16 CPU usage of a single machine in the experiment of 5 SMD devices下载:
全尺寸图片
图 16 5台SMD设备实验中单机CPU占用情况Fig. 16 CPU usage of a single machine in the experiment of 5 SMD devices下载:
全尺寸图片
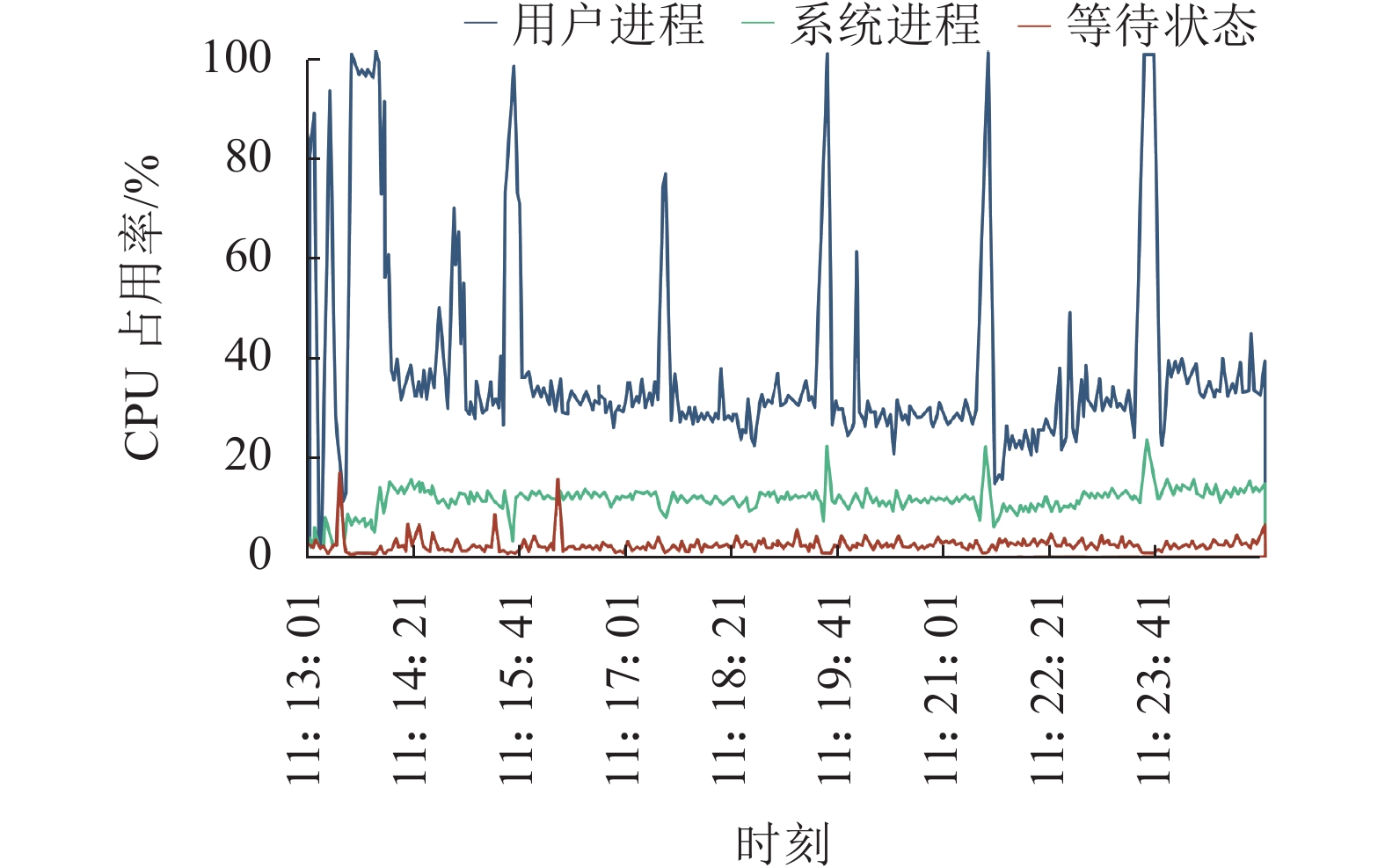 图 17 5台SMD设备实验中集群CPU占用情况Fig. 17 Cluster CPU usage in the experiment of 5 SMD devices下载:
全尺寸图片
图 17 5台SMD设备实验中集群CPU占用情况Fig. 17 Cluster CPU usage in the experiment of 5 SMD devices下载:
全尺寸图片
表3是针对同一区域内5台SMD-L设备上传数据,扰动初判运算在集群和单机运算中的实际效果展示。由表3可以看出,相对于原主站应用平台采用的单机运算方式,新型分布式应用平台拥有更快的数据处理速度,这使得主站可以更快识别系统异常运行状态。在Bolt运算发现疑似扰动后,该事件结果将流向下一级Bolt,协同分析该时间段内L、R、C侧数据,进行下一步的扰动判别与定位运算,该过程在Storm集群与单机多线程中运算效果如表4所示。
表 3 利用L侧数据进行扰动初判运算效果对比情况Table 3 Comparison of computing effects of using L-side data for the initial judgment of disturbance运算方式 平均计算
延时/s最快输出
时间/s最慢输出
时间/sStorm集群运算 4.395 3.515 5.386 单机多线程运算 17.074 15.307 18.534 表 4 利用L、R、C侧数据扰动判别与定位运算效果对比情况Table 4 Comparison of computing effects of using L-, R-, C-side data for disturbance discrimination and localization运算方式 平均计算
延时/s最快输出
时间/s最慢输出
时间/sStorm集群运算 9.572 7.422 10.955 单机多线程运算 24.010 22.001 24.881 从表3、4的运算延时效果来看,Storm集群通过分布式分配任务,单算法运算性能高于单机计算。由于SYMS主站应用平台中包含着多级的处理流程,单个算法运算完毕后需将事件识别结果发送至下一级才能开始后续运算,因此,Storm分布式计算可以缩短总体运算时间,并且,多节点运算速度存在差异,错峰发送的事件识别结果也可以缓解整个集群的运算压力。此外,Bolt在一个时刻只能执行取数操作或调用算法操作。长时间的算法调用会导致Bolt无法取到实时数据,在一段时间后调用算法时,Bolt会因为采集数据数量较少而造成算法调用失败,影响系统稳定性。
3.3 SYMS分布式主站的整体测试
目前,本文提出的基于OpenPDC的多源异类数据实时处理方法及基于Storm的分布式运算方式已经在SYMS主站系统中测试并投入使用。图18、19为主站前置平台将数据解析后,分布式计算平台Storm实时分析数据检测到扰动事件时,在SYMS网页端输出的识别结果与扰动期间的频率测量数据展示。由图18、19所示的在南京和泰宁的单机数据分析可知:Storm系统通过扰动初判识别出该事件,通过同一区域内相邻设备的数据协同分析,判断出这并非坏数据,而是发生了真实扰动。在将扰动期间数据提取展示后,通过查阅了国家电网公司的系统事故报告,确认本次事件是由于临近的发电厂大规模切机,导致南京和泰宁地区都发生了频率扰动。
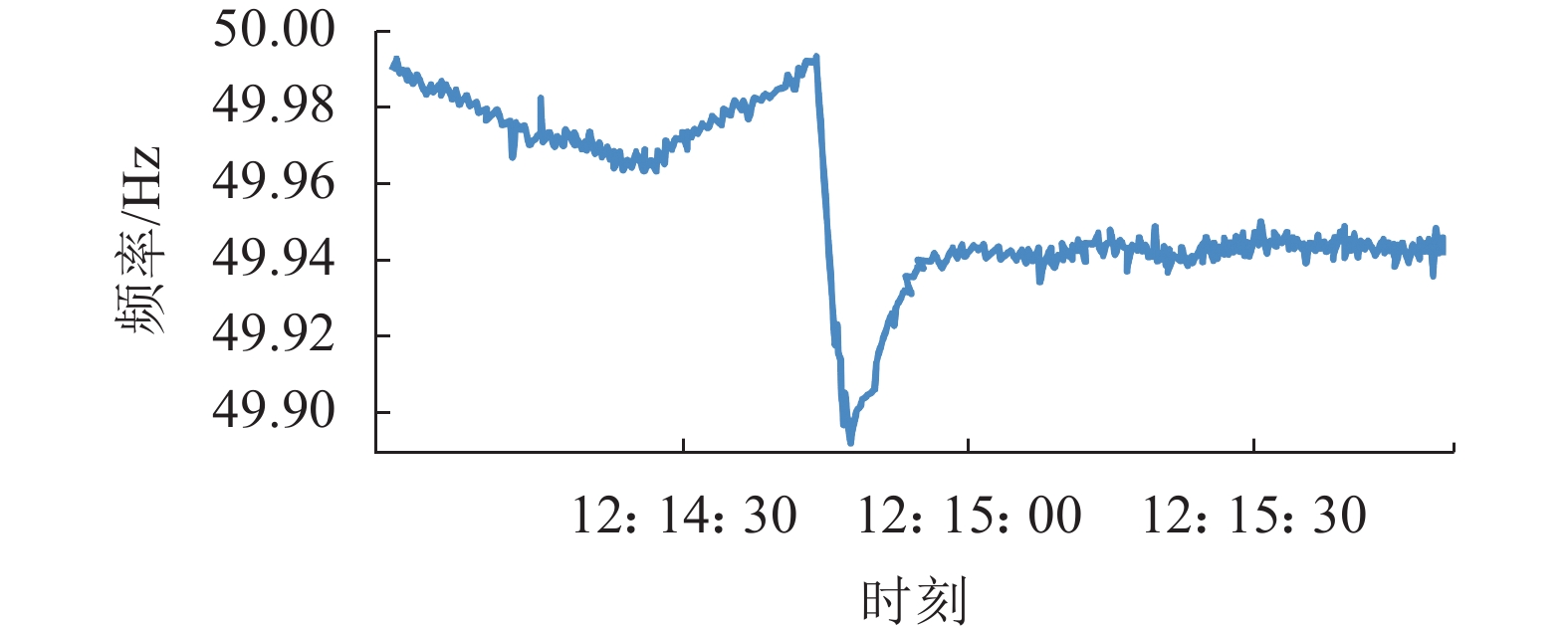 图 18 南京SMD-L检测到切机引起扰动时的频率测量数据Fig. 18 Frequency measurement data when Nanjing SMD-L detects disturbance due to mass cutters下载:
全尺寸图片
图 18 南京SMD-L检测到切机引起扰动时的频率测量数据Fig. 18 Frequency measurement data when Nanjing SMD-L detects disturbance due to mass cutters下载:
全尺寸图片
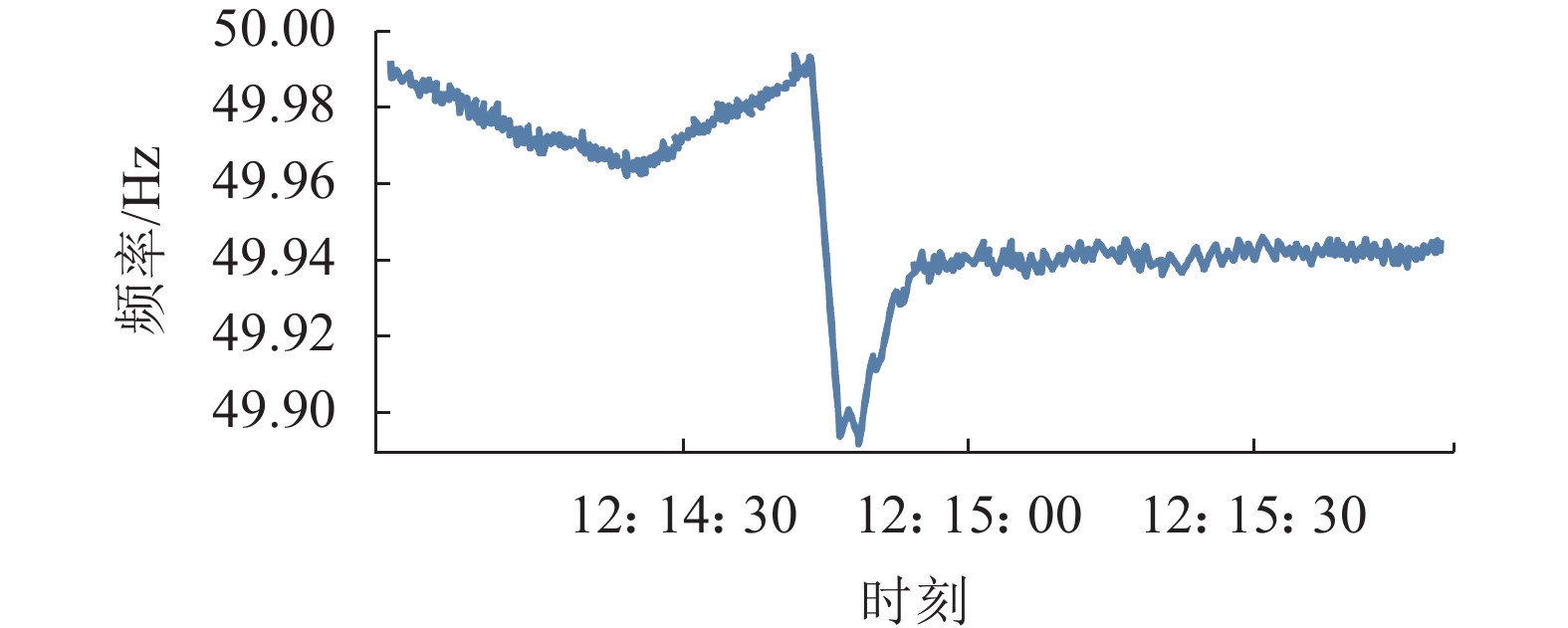 图 19 泰宁SMD-L检测到切机引起扰动时的频率测量数据Fig. 19 SMD location map frequency measurement data when Taining SMD-L detects disturbance due to mass cutters下载:
全尺寸图片
图 19 泰宁SMD-L检测到切机引起扰动时的频率测量数据Fig. 19 SMD location map frequency measurement data when Taining SMD-L detects disturbance due to mass cutters下载:
全尺寸图片
图20为南京负荷侧SMD-L装置在扰动期间测量的一段频率数据。由图20可知:Storm系统在实时识别到扰动发生后,将该段时间数据提取并展示在SYMS网页端。后期经过事故检索,发现其由于附近电网发生相间故障而导致的局部扰动。通过对比性实验与实际运行效果的分析,基于流处理框架的Storm系统拥有运算延时低、资源可扩展、运行稳定的优势。因此,引入Storm分布式计算对于SYMS主站的可靠运行具有重要意义。
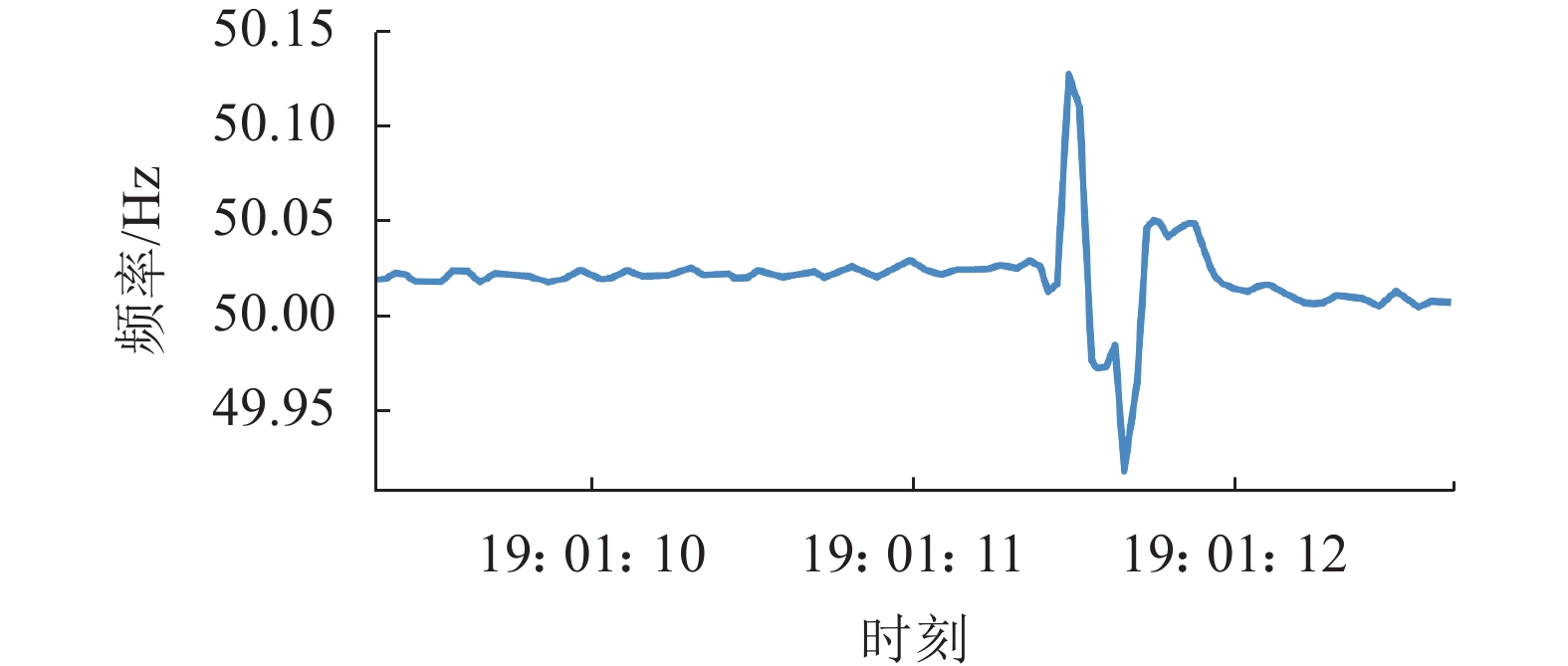 图 20 南京SMD-L检测到相间故障引起扰动时的频率测量数据Fig. 20 Frequency measurement data when Nanjing SMD-L detects disturbance due to phase-to-phase faults下载:
全尺寸图片
图 20 南京SMD-L检测到相间故障引起扰动时的频率测量数据Fig. 20 Frequency measurement data when Nanjing SMD-L detects disturbance due to phase-to-phase faults下载:
全尺寸图片
3.4 分布式主站可推广性分析
在新型SYMS分布式主站部署过程中,本文所提设计方法采用私有云[23]模型,利用Vmware Vsphere[24]虚拟化技术将每台服务器虚拟为多个逻辑计算机,将其并行运行,搭建分布式主站所需的集群环境。Vsphere技术支持整合异构的操作系统,且不限制硬件资源分割尺度,这不但减小了分布式主站的建设成本,也使得主站可以根据实际运行情况以更精细的颗粒度分配计算资源,在面向不同规模、不同复杂度系统时也可拥有良好运行效果。
在主站应用平台部署过程中,以Apache Thrift[25]为基础的Storm支持多语言接口协议,确保了多种算法均可在Storm系统中可靠运行,并保持了较快的运算速度。此外,Storm将消息树作为整体进行追踪,通过对消息ID进行异或运算判断整棵消息树是否被完全处理,树中任何一条消息失败后,主节点将指挥该条信息发送至其他节点展开运算,确保系统的持续稳定运行。综上,本文提出的SYMS系统分布式主站设计方法具有良好的可推广性。
4. 结 论
本文以源网荷全景同步测量系统主站为主要研究对象,提出了基于分布式架构的SYMS主站。首先,基于开源同步相量数据集中器OpenPDC开发了多源异类数据实时处理方法,设计实现了基于HAProxy的前置负载均衡集群。其次,基于流处理框架Storm开发了针对扰动初判算法的分布式运算方式,该运算方式可推广至不同语言、不同窗长的电力系统算法。最后,对分布式主站进行了性能测试。
分布式主站的开发和实现使得SYMS系统可以具备高计算能力与良好的横向扩展能力。面对系统布点数量的提升,只需在集群中添加更多机器来增强集群处理能力,而不需修改系统处理逻辑。针对运算效率要求更高的主站应用平台,本文所提方法未考虑对搭载算法本身进行优化,以提高主站监测实时性的方式。下一步的研究工作中,将针对应用平台中运算延时较高的环节进行算法层面优化,并针对电力系统算法特点,优化Storm集群中资源调度与任务分配的逻辑,进一步缩短处理延时,提高分布式主站的性能。
-
图 1 SYMS系统整体架构图
Fig. 1 Overall architecture diagram of SYMS
下载:
全尺寸图片
图 2 SMD装置配置帧结构图
Fig. 2 Structure diagram of SMD configuration
下载:
全尺寸图片
图 3 SMD装置数据帧结构图
Fig. 3 Structure diagram of SMD data frame
下载:
全尺寸图片
图 4 适用于SYMS的多源异类数据适配器程序流程图
Fig. 4 Flowchart of multisource heterogeneous data adapter program for SYMS
下载:
全尺寸图片
图 5 异步队列缓冲区
Fig. 5 Asynchronous queue buffer
下载:
全尺寸图片
图 6 帧头公共部分解析方法
Fig. 6 Parsing method of the frame header’s public part
下载:
全尺寸图片
图 7 基波数据帧多线程处理流程图
Fig. 7 Flow chart of multi-thread processing of fundamental wave data frame
下载:
全尺寸图片
图 8 Storm集群外部框架图
Fig. 8 Framework diagram of Storm cluster
下载:
全尺寸图片
图 9 SYMS主站应用平台运行逻辑图
Fig. 9 Logic diagram of SYMS master station’s application platform
下载:
全尺寸图片
图 10 Storm拓扑与集群对应关系
Fig. 10 Correspondence of Storm topology and Storm cluster
下载:
全尺寸图片
图 11 Kafka集群实现异步通信的框架图
Fig. 11 Framework diagram of asynchronous communication using Kafka cluster
下载:
全尺寸图片
图 12 利用触发信号控制算法调用的拓扑概念图
Fig. 12 Conceptual diagram of topology using trigger signals to control algorithm calls
下载:
全尺寸图片
图 13 前置负载均衡集群架构图
Fig. 13 Front load balancing cluster architecture diagram
下载:
全尺寸图片
图 14 前置负载均衡集群各节点分配连接数
Fig. 14 Number of connections allocated to each node of the front load balancing cluster
下载:
全尺寸图片
图 15 单机与集群节点负载量对比
Fig. 15 Comparison of the load of a single machine and a cluster node
下载:
全尺寸图片
图 16 5台SMD设备实验中单机CPU占用情况
Fig. 16 CPU usage of a single machine in the experiment of 5 SMD devices
下载:
全尺寸图片
图 17 5台SMD设备实验中集群CPU占用情况
Fig. 17 Cluster CPU usage in the experiment of 5 SMD devices
下载:
全尺寸图片
图 18 南京SMD-L检测到切机引起扰动时的频率测量数据
Fig. 18 Frequency measurement data when Nanjing SMD-L detects disturbance due to mass cutters
下载:
全尺寸图片
图 19 泰宁SMD-L检测到切机引起扰动时的频率测量数据
Fig. 19 SMD location map frequency measurement data when Taining SMD-L detects disturbance due to mass cutters
下载:
全尺寸图片
图 20 南京SMD-L检测到相间故障引起扰动时的频率测量数据
Fig. 20 Frequency measurement data when Nanjing SMD-L detects disturbance due to phase-to-phase faults
下载:
全尺寸图片
表 1 不同SMD设备的测量数据特征
Table 1 Data characteristics of different SMDs
不同SMD 数据类型 测量频带/Hz 上传频率/Hz SMD-R 基波 20~80 50 间谐波 0~20、80~100 1 SMD-C 基波 48~52 100 SMD-L 基波 45~55 50 谐波 0~45、55~100 1 间谐波 2次~50次谐波 1 表 2 虚拟机硬件参数及实验平台
Table 2 Virtual machine hardware parameters and experimental platform
虚拟机类型 虚拟CPU
个数内存/GB 操作系统 实验平台 Kafka虚拟机 2 8 CentOS7 Kafka2.11、
Zookeeper3.6.3Storm虚拟机 2 8 CentOS7 Storm1.2.3、
Zookeeper3.6.3、
MCR 9.2表 3 利用L侧数据进行扰动初判运算效果对比情况
Table 3 Comparison of computing effects of using L-side data for the initial judgment of disturbance
运算方式 平均计算
延时/s最快输出
时间/s最慢输出
时间/sStorm集群运算 4.395 3.515 5.386 单机多线程运算 17.074 15.307 18.534 表 4 利用L、R、C侧数据扰动判别与定位运算效果对比情况
Table 4 Comparison of computing effects of using L-, R-, C-side data for disturbance discrimination and localization
运算方式 平均计算
延时/s最快输出
时间/s最慢输出
时间/sStorm集群运算 9.572 7.422 10.955 单机多线程运算 24.010 22.001 24.881 -
[1] 胡家兵,袁小明,程时杰.电力电子并网装备多尺度切换控制与电力电子化电力系统多尺度暂态问题[J].中国电机工程学报,2019,39(18):5457–5467. doi: 10.13334/j.0258-8013.pcsee.190052 Hu Jiabing,Yuan Xiaoming,Cheng Shijie.Multi-time scale transients in power-electronized power systems considering multi-time scale switching control schemes of power electronics apparatus[J].Proceedings of the CSEE,2019,39(18):5457–5467 doi: 10.13334/j.0258-8013.pcsee.190052 [2] Shakerighadi B,Peyghami S,Ebrahimzadeh E,et al.Security analysis of power electronic-based power systems[C]//Proceedings of the IECON 2019-45th Annual Conference of the IEEE Industrial Electronics Society.Lisbon:IEEE,2019:4933–4937. [3] 谢小荣,贺静波,毛航银,等.“双高”电力系统稳定性的新问题及分类探讨[J].中国电机工程学报,2021,41(2):461–475. doi: 10.13334/j.0258-8013.pcsee.201405 Xie Xiaorong,He Jingbo,Mao Hangyin,et al.New issues and classification of power system stability with high shares of renewables and power electronics[J].Proceedings of the CSEE,2021,41(2):461–475 doi: 10.13334/j.0258-8013.pcsee.201405 [4] 周孝信,陈树勇,鲁宗相,等.能源转型中我国新一代电力系统的技术特征[J].中国电机工程学报,2018,38(7):1893–1904. doi: 10.13334/j.0258-8013.pcsee.180067 Zhou Xiaoxin,Chen Shuyong,Lu Zongxiang,et al.Technology features of the new generation power system in China[J].Proceedings of the CSEE,2018,38(7):1893–1904 doi: 10.13334/j.0258-8013.pcsee.180067 [5] 赵哲宇.源网荷全景同步测量系统主站数据处理与分析方法研究[D].北京:华北电力大学(北京),2021. Zhao Zheyu.Research on data processing and analysis method of full-view synchronized measurement system master station for renewable sources,grid and load[D].Beijing:North China Electric Power University,2021. [6] Liu Hao,Li Jue,Li Jiaxian,et al.Synchronised measurement devices for power systems with high penetration of inverter-based renewable power generators[J].IET Renewable Power Generation,2019,13(1):40–48. doi: 10.1049/iet-rpg.2018.5207 [7] Phadke A G,Thorp J S.Synchronized phasor measurements and their applications[M].New York:Springer,2008. [8] Li Yi,Shi Fang,Zhang Hengxu.Panoramic synchronous measurement system for wide-area power system based on the cloud computing[C]//Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications(ICIEA).Wuhan:IEEE,2018:764–768. [9] Gardner R M,Liu Yilu.FNET:A quickly deployable and economic system to monitor the electric grid[C]//Proceedings of the 2007 IEEE Conference on Technologies for Homeland Security.Woburn:IEEE,2007:209–214. [10] Zhou Dao,Guo Jiahui,Zhang Ye,et al.Distributed data analytics platform for wide-area synchrophasor measurement systems[J].IEEE Transactions on Smart Grid,2016,7(5):2397–2405. doi: 10.1109/TSG.2016.2528895 [11] Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems,2008,26(2):1–26. doi: 10.1145/1365815.1365816 [12] Dean J,Ghemawat S.MapReduce[J].Communications of the ACM,2008,51(1):107–113. doi: 10.1145/1327452.1327492 [13] Bhandarkar M.MapReduce programming with apache hadoop[C]//Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing(IPDPS).Atlanta:IEEE,2010:No.11324108. [14] Hussain Iqbal M,Szabist,Rahim Soomro T.Big data analysis:Apache storm perspective[J].International Journal of Computer Trends and Technology,2015,19(1):9–14. doi: 10.14445/22312803/ijctt-v19p103 [15] Alnafessah A,Casale G.AI driven methodology for anomaly detection in apache spark streaming systems[C]//Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security(ICCAIS).Riyadh:IEEE,2020:No.19632306. [16] 田建南.源网荷全景同步测量系统通信接入技术研究[D].北京:华北电力大学(北京),2019. Tian Jiannan.Research on communication access technology for A full-view synchronized measurement system[D].Beijing:North China Electric Power University,2019. [17] Apache Strom.Apache storm documentation[EB/OL].[2022–01–06].https://storm.apache.org. [18] Thein K M M.Apache kafka:Next generation distributed messaging system[J].International Journal of Scientific Engineering and Technology Research,2014,3(47):9478–9483. [19] Wu Han.Research proposal:Reliability evaluation of the apache Kafka streaming system[C]//Proceedings of the 2019 IEEE International Symposium on Software Reliability Engineering Workshops(ISSREW).Berlin:IEEE,2020:112–113. [20] 邬林.基于消息队列的用电信息采集技术的研究与实现[D].北京:华北电力大学(北京),2019. Wu Lin.Research and implementation of information collection technology based on message queue[D].Beijing:North China Electric Power University,2019. [21] 雷志成.基于服务器集群的负载均衡调度系统的设计与实现[D].北京:北京邮电大学,2021. Lei Zhicheng.Design and implementation of load balancing scheduling system based on server cluster[D].Beijing:Beijing University of Posts and Telecommunications,2021. [22] Pramono L H,Buwono R C,Waskito Y G.Round-robin algorithm in HAProxy and nginx load balancing performance evaluation:A review[C]//Proceedings of the 2018 International Seminar on Research of Information Technology and Intelligent Systems(ISRITI).Yogyakarta:IEEE,2019:367–372. [23] 罗兵,谯英,符晓.OpenStack云平台的高可用设计与实现[J].计算机科学,2017,44(增刊1):563–566. doi: 10.11896/j.issn.1002-137X.2017.6A.126 Luo Bing,Qiao Ying,Fu Xiao.Design and implementation of high-availability based on OpenStack cloud platform[J].Computer Science,2017,44(Supp1):563–566 doi: 10.11896/j.issn.1002-137X.2017.6A.126 [24] Kurniawan D E,Nashrullah M,Kurniasih N,et al.Performance analysis virtual server VMware Vsphere 5.5 with physical enterprise server[J].IOP Conference Series:Materials Science and Engineering,2018,420:012107. doi: 10.1088/1757-899x/420/1/012107 [25] Kodithuwakku S,Padmakumara L,Premadasa I,et al.GajaNindu:A distributed system management framework with user-defined management logic[C]//Proceedings of the 2013 10th International Conference on Information Technology:New Generations.Las Vegas:IEEE,2013:83–88.

